* Translate 1.0.0b6 release with the machine learning translator. * Update Dockerfile A few translation improvements. * Fix a badge logo. * Fix EN translation of chapter_appendix/terminology.md (#913) * Update README.md * Update README.md * translation: Refined the automated translation of README (#932) * refined the automated translation of README * Update index.md * Update mkdocs-en.yml --------- Co-authored-by: Yudong Jin <krahets@163.com> * translate: Embellish chapter_computational_complexity/index.md (#940) * translation: Update chapter_computational_complexity/performance_evaluation.md (#943) * Update performance_evaluation.md * Update performance_evaluation.md * Update performance_evaluation.md change 'methods' to 'approaches' on line 15 * Update performance_evaluation.md on line 21, change the sentence to 'the results could be the opposite on another computer with different specifications.' * Update performance_evaluation.md delete two short sentence on line 5 and 6 * Update performance_evaluation.md change `unavoidable` to `inevitable` on line 48 * Update performance_evaluation.md small changes on line 23 * translation: Update terminology and improve readability in preface summary (#954) * Update terminology and improve readability in preface summary This commit made a few adjustments in the 'summary.md' file for clearer and more accessible language. "Brushing tool library" was replaced with "Coding Toolkit" to better reflect common terminology. Also, advice for beginners in algorithm learning journey was reformulated to imply a more positive approach avoiding detours and common pitfalls. The section related to the discussion forum was rewritten to sound more inviting to readers. * Format * Optimize the translation of chapter_introduction/algorithms_are_everywhere. * Add .gitignore to Java subfolder. * Update the button assets. * Fix the callout * translation: chapter_computational_complexity/summary to en (#953) * translate chapter_computational_complexity/summary * minor format * Update summary.md with comment * Update summary.md * Update summary.md * translation: chapter_introduction/what_is_dsa.md (#962) * Optimize translation of what_is_dsa.md * Update * translation: chapter_introduction/summary.md (#963) * Translate chapter_introduction/summary.md * Update * translation: Update README.md (#964) * Update en translation of README.md * Update README.md * translation: update space_complexity.md (#970) * update space_complexity.md * the rest of translation piece * Update space_complexity.md --------- Co-authored-by: ThomasQiu <thomas.qiu@mnfgroup.limited> Co-authored-by: Yudong Jin <krahets@163.com> * translation: Update chapter_introduction/index.md (#971) * Update index.md sorry, first time doing this... now this is the final change. changes: title of the chapter is shorter. refined the abstract. * Update index.md --------- Co-authored-by: Yudong Jin <krahets@163.com> * translation: Update chapter_data_structure/classification_of_data_structure.md (#980) * update classification_of_data_structure.md * Update classification_of_data_structure.md --------- Co-authored-by: Yudong Jin <krahets@163.com> * translation: Update chapter_introduction/algorithms_are_everywhere.md (#972) * Update algorithms_are_everywhere.md changed or refined parts of the words and sentences including tips. Some of them I didnt change that much because im worried that it might not meet the requirement of accuracy. some other ones i changed a lot to make it sound better, but also kind of following the same wording as the CN version * Update algorithms_are_everywhere.md re-edited the dictionary part from Piyin to just normal Eng dictionary. again thank you very much hpstory for you suggestion. * Update algorithms_are_everywhere.md --------- Co-authored-by: Yudong Jin <krahets@163.com> * Prepare merging into main branch. * Update buttons * Update Dockerfile * Update index.md * Update index.md * Update README * Fix index.md * Fix mkdocs-en.yml --------- Co-authored-by: Yuelin Xin <sc20yx2@leeds.ac.uk> Co-authored-by: Phoenix Xie <phoenixx0415@gmail.com> Co-authored-by: Sizhuo Long <longsizhuo@gmail.com> Co-authored-by: Spark <qizhang94@outlook.com> Co-authored-by: Thomas <thomasqiu7@gmail.com> Co-authored-by: ThomasQiu <thomas.qiu@mnfgroup.limited> Co-authored-by: K3v123 <123932560+K3v123@users.noreply.github.com> Co-authored-by: Jin <36914748+yanedie@users.noreply.github.com>
36 KiB
Time Complexity
Runtime can be a visual and accurate reflection of the efficiency of an algorithm. What should we do if we want to accurately predict the runtime of a piece of code?
- Determine the running platform, including hardware configuration, programming language, system environment, etc., all of which affect the efficiency of the code.
- Evaluates the running time required for various computational operations, e.g., the addition operation
+takes 1 ns, the multiplication operation*takes 10 ns, the print operationprint()takes 5 ns, and so on. - Counts all the computational operations in the code and sums the execution times of all the operations to get the runtime.
For example, in the following code, the input data size is n :
=== "Python"
```python title=""
# Under an operating platform
def algorithm(n: int):
a = 2 # 1 ns
a = a + 1 # 1 ns
a = a * 2 # 10 ns
# Cycle n times
for _ in range(n): # 1 ns
print(0) # 5 ns
```
=== "C++"
```cpp title=""
// Under a particular operating platform
void algorithm(int n) {
int a = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
cout << 0 << endl; // 5 ns
}
}
```
=== "Java"
```java title=""
// Under a particular operating platform
void algorithm(int n) {
int a = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
System.out.println(0); // 5 ns
}
}
```
=== "C#"
```csharp title=""
// Under a particular operating platform
void Algorithm(int n) {
int a = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
Console.WriteLine(0); // 5 ns
}
}
```
=== "Go"
```go title=""
// Under a particular operating platform
func algorithm(n int) {
a := 2 // 1 ns
a = a + 1 // 1 ns
a = a * 2 // 10 ns
// Loop n times
for i := 0; i < n; i++ { // 1 ns
fmt.Println(a) // 5 ns
}
}
```
=== "Swift"
```swift title=""
// Under a particular operating platform
func algorithm(n: Int) {
var a = 2 // 1 ns
a = a + 1 // 1 ns
a = a * 2 // 10 ns
// Loop n times
for _ in 0 ..< n { // 1 ns
print(0) // 5 ns
}
}
```
=== "JS"
```javascript title=""
// Under a particular operating platform
function algorithm(n) {
var a = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for(let i = 0; i < n; i++) { // 1 ns , every round i++ is executed
console.log(0); // 5 ns
}
}
```
=== "TS"
```typescript title=""
// Under a particular operating platform
function algorithm(n: number): void {
var a: number = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for(let i = 0; i < n; i++) { // 1 ns , every round i++ is executed
console.log(0); // 5 ns
}
}
```
=== "Dart"
```dart title=""
// Under a particular operating platform
void algorithm(int n) {
int a = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
print(0); // 5 ns
}
}
```
=== "Rust"
```rust title=""
// Under a particular operating platform
fn algorithm(n: i32) {
let mut a = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for _ in 0..n { // 1 ns for each round i++
println!("{}", 0); // 5 ns
}
}
```
=== "C"
```c title=""
// Under a particular operating platform
void algorithm(int n) {
int a = 2; // 1 ns
a = a + 1; // 1 ns
a = a * 2; // 10 ns
// Loop n times
for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
printf("%d", 0); // 5 ns
}
}
```
=== "Zig"
```zig title=""
// Under a particular operating platform
fn algorithm(n: usize) void {
var a: i32 = 2; // 1 ns
a += 1; // 1 ns
a *= 2; // 10 ns
// Loop n times
for (0..n) |_| { // 1 ns
std.debug.print("{}\n", .{0}); // 5 ns
}
}
```
Based on the above method, the algorithm running time can be obtained as 6n + 12 ns :
$$
1 + 1 + 10 + (1 + 5) \times n = 6n + 12
In practice, however, statistical algorithm runtimes are neither reasonable nor realistic. First, we do not want to tie the estimation time to the operation platform, because the algorithm needs to run on a variety of different platforms. Second, it is difficult for us to be informed of the runtime of each operation, which makes the prediction process extremely difficult.
Trends In Statistical Time Growth
The time complexity analysis counts not the algorithm running time, but the tendency of the algorithm running time to increase as the amount of data gets larger.
The concept of "time-growing trend" is rather abstract, so let's try to understand it through an example. Suppose the size of the input data is n, and given three algorithmic functions A, B and C:
=== "Python"
```python title=""
# Time complexity of algorithm A: constant order
def algorithm_A(n: int):
print(0)
# Time complexity of algorithm B: linear order
def algorithm_B(n: int):
for _ in range(n):
print(0)
# Time complexity of algorithm C: constant order
def algorithm_C(n: int):
for _ in range(1000000):
print(0)
```
=== "C++"
```cpp title=""
// Time complexity of algorithm A: constant order
void algorithm_A(int n) {
cout << 0 << endl;
}
// Time complexity of algorithm B: linear order
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
cout << 0 << endl;
}
}
// Time complexity of algorithm C: constant order
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
cout << 0 << endl;
}
}
```
=== "Java"
```java title=""
// Time complexity of algorithm A: constant order
void algorithm_A(int n) {
System.out.println(0);
}
// Time complexity of algorithm B: linear order
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
System.out.println(0);
}
}
// Time complexity of algorithm C: constant order
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
System.out.println(0);
}
}
```
=== "C#"
```csharp title=""
// Time complexity of algorithm A: constant order
void AlgorithmA(int n) {
Console.WriteLine(0);
}
// Time complexity of algorithm B: linear order
void AlgorithmB(int n) {
for (int i = 0; i < n; i++) {
Console.WriteLine(0);
}
}
// Time complexity of algorithm C: constant order
void AlgorithmC(int n) {
for (int i = 0; i < 1000000; i++) {
Console.WriteLine(0);
}
}
```
=== "Go"
```go title=""
// Time complexity of algorithm A: constant order
func algorithm_A(n int) {
fmt.Println(0)
}
// Time complexity of algorithm B: linear order
func algorithm_B(n int) {
for i := 0; i < n; i++ {
fmt.Println(0)
}
}
// Time complexity of algorithm C: constant order
func algorithm_C(n int) {
for i := 0; i < 1000000; i++ {
fmt.Println(0)
}
}
```
=== "Swift"
```swift title=""
// Time complexity of algorithm A: constant order
func algorithmA(n: Int) {
print(0)
}
// Time complexity of algorithm B: linear order
func algorithmB(n: Int) {
for _ in 0 ..< n {
print(0)
}
}
// Time complexity of algorithm C: constant order
func algorithmC(n: Int) {
for _ in 0 ..< 1000000 {
print(0)
}
}
```
=== "JS"
```javascript title=""
// Time complexity of algorithm A: constant order
function algorithm_A(n) {
console.log(0);
}
// Time complexity of algorithm B: linear order
function algorithm_B(n) {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// Time complexity of algorithm C: constant order
function algorithm_C(n) {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
```
=== "TS"
```typescript title=""
// Time complexity of algorithm A: constant order
function algorithm_A(n: number): void {
console.log(0);
}
// Time complexity of algorithm B: linear order
function algorithm_B(n: number): void {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// Time complexity of algorithm C: constant order
function algorithm_C(n: number): void {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
```
=== "Dart"
```dart title=""
// Time complexity of algorithm A: constant order
void algorithmA(int n) {
print(0);
}
// Time complexity of algorithm B: linear order
void algorithmB(int n) {
for (int i = 0; i < n; i++) {
print(0);
}
}
// Time complexity of algorithm C: constant order
void algorithmC(int n) {
for (int i = 0; i < 1000000; i++) {
print(0);
}
}
```
=== "Rust"
```rust title=""
// Time complexity of algorithm A: constant order
fn algorithm_A(n: i32) {
println!("{}", 0);
}
// Time complexity of algorithm B: linear order
fn algorithm_B(n: i32) {
for _ in 0..n {
println!("{}", 0);
}
}
// Time complexity of algorithm C: constant order
fn algorithm_C(n: i32) {
for _ in 0..1000000 {
println!("{}", 0);
}
}
```
=== "C"
```c title=""
// Time complexity of algorithm A: constant order
void algorithm_A(int n) {
printf("%d", 0);
}
// Time complexity of algorithm B: linear order
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
printf("%d", 0);
}
}
// Time complexity of algorithm C: constant order
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
printf("%d", 0);
}
}
```
=== "Zig"
```zig title=""
// Time complexity of algorithm A: constant order
fn algorithm_A(n: usize) void {
_ = n;
std.debug.print("{}\n", .{0});
}
// Time complexity of algorithm B: linear order
fn algorithm_B(n: i32) void {
for (0..n) |_| {
std.debug.print("{}\n", .{0});
}
}
// Time complexity of algorithm C: constant order
fn algorithm_C(n: i32) void {
_ = n;
for (0..1000000) |_| {
std.debug.print("{}\n", .{0});
}
}
```
The figure below shows the time complexity of the above three algorithmic functions.
- Algorithm
Ahas only1print operations, and the running time of the algorithm does not increase withn. We call the time complexity of this algorithm "constant order". - The print operation in algorithm
Brequiresncycles, and the running time of the algorithm increases linearly withn. The time complexity of this algorithm is called "linear order". - The print operation in algorithm
Crequires1000000loops, which is a long runtime, but it is independent of the size of the input datan. Therefore, the time complexity ofCis the same as that ofA, which is still of "constant order".

What are the characteristics of time complexity analysis compared to direct statistical algorithmic running time?
- The time complexity can effectively evaluate the efficiency of an algorithm. For example, the running time of algorithm
Bincreases linearly and is slower than algorithmAforn > 1and slower than algorithmCforn > 1,000,000. In fact, as long as the input data sizenis large enough, algorithms with "constant order" of complexity will always outperform algorithms with "linear order", which is exactly what the time complexity trend means. - The time complexity of the projection method is simpler. Obviously, neither the running platform nor the type of computational operation is related to the growth trend of the running time of the algorithm. Therefore, in the time complexity analysis, we can simply consider the execution time of all computation operations as the same "unit time", and thus simplify the "statistics of the running time of computation operations" to the "statistics of the number of computation operations", which is the same as the "statistics of the number of computation operations". The difficulty of the estimation is greatly reduced by considering the execution time of all operations as the same "unit time".
- There are also some limitations of time complexity. For example, although algorithms
AandChave the same time complexity, the actual running time varies greatly. Similarly, although the time complexity of algorithmBis higher than that ofC, algorithmBsignificantly outperforms algorithmCwhen the size of the input datanis small. In these cases, it is difficult to judge the efficiency of an algorithm based on time complexity alone. Of course, despite the above problems, complexity analysis is still the most effective and commonly used method to judge the efficiency of algorithms.
Functions Asymptotic Upper Bounds
Given a function with input size n:
=== "Python"
```python title=""
def algorithm(n: int):
a = 1 # +1
a = a + 1 # +1
a = a * 2 # +1
# Cycle n times
for i in range(n): # +1
print(0) # +1
```
=== "C++"
```cpp title=""
void algorithm(int n) {
int a = 1; // +1
a = a + 1; // +1
a = a * 2; // +1
// Loop n times
for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
cout << 0 << endl; // +1
}
}
```
=== "Java"
```java title=""
void algorithm(int n) {
int a = 1; // +1
a = a + 1; // +1
a = a * 2; // +1
// Loop n times
for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
System.out.println(0); // +1
}
}
```
=== "C#"
```csharp title=""
void Algorithm(int n) {
int a = 1; // +1
a = a + 1; // +1
a = a * 2; // +1
// Loop n times
for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
Console.WriteLine(0); // +1
}
}
```
=== "Go"
```go title=""
func algorithm(n int) {
a := 1 // +1
a = a + 1 // +1
a = a * 2 // +1
// Loop n times
for i := 0; i < n; i++ { // +1
fmt.Println(a) // +1
}
}
```
=== "Swift"
```swift title=""
func algorithm(n: Int) {
var a = 1 // +1
a = a + 1 // +1
a = a * 2 // +1
// Loop n times
for _ in 0 ..< n { // +1
print(0) // +1
}
}
```
=== "JS"
```javascript title=""
function algorithm(n) {
var a = 1; // +1
a += 1; // +1
a *= 2; // +1
// Loop n times
for(let i = 0; i < n; i++){ // +1 (execute i ++ every round)
console.log(0); // +1
}
}
```
=== "TS"
```typescript title=""
function algorithm(n: number): void{
var a: number = 1; // +1
a += 1; // +1
a *= 2; // +1
// Loop n times
for(let i = 0; i < n; i++){ // +1 (execute i ++ every round)
console.log(0); // +1
}
}
```
=== "Dart"
```dart title=""
void algorithm(int n) {
int a = 1; // +1
a = a + 1; // +1
a = a * 2; // +1
// Loop n times
for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
print(0); // +1
}
}
```
=== "Rust"
```rust title=""
fn algorithm(n: i32) {
let mut a = 1; // +1
a = a + 1; // +1
a = a * 2; // +1
// Loop n times
for _ in 0..n { // +1 (execute i ++ every round)
println!("{}", 0); // +1
}
}
```
=== "C"
```c title=""
void algorithm(int n) {
int a = 1; // +1
a = a + 1; // +1
a = a * 2; // +1
// Loop n times
for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
printf("%d", 0); // +1
}
}
```
=== "Zig"
```zig title=""
fn algorithm(n: usize) void {
var a: i32 = 1; // +1
a += 1; // +1
a *= 2; // +1
// Loop n times
for (0..n) |_| { // +1 (execute i ++ every round)
std.debug.print("{}\n", .{0}); // +1
}
}
```
Let the number of operations of the algorithm be a function of the size of the input data n, denoted as T(n) , then the number of operations of the above function is:
$$
T(n) = 3 + 2n
T(n) is a primary function, which indicates that the trend of its running time growth is linear, and thus its time complexity is of linear order.
We denote the time complexity of the linear order as O(n) , and this mathematical notation is called the "big O notation big-O notation", which denotes the "asymptotic upper bound" of the function T(n).
Time complexity analysis is essentially the computation of asymptotic upper bounds on the "number of operations function $T(n)$", which has a clear mathematical definition.
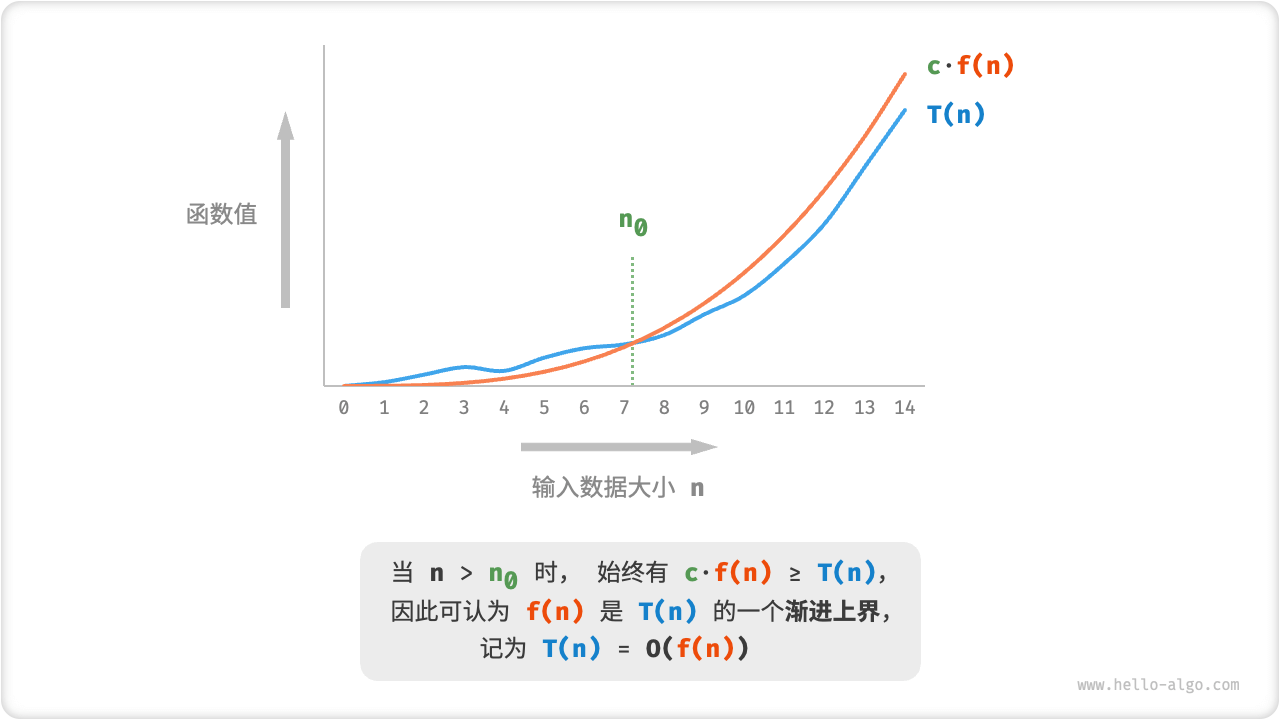
!!! abstract "Function asymptotic upper bound"
If there exists a positive real number $c$ and a real number $n_0$ such that $T(n) \leq c \cdot f(n)$ for all $n > n_0$ , then it can be argued that $f(n)$ gives an asymptotic upper bound on $T(n)$ , denoted as $T(n) = O(f(n))$ .
As shown in the figure below, computing the asymptotic upper bound is a matter of finding a function f(n) such that T(n) and f(n) are at the same growth level as n tends to infinity, differing only by a multiple of the constant term c.
Method Of Projection
Asymptotic upper bounds are a bit heavy on math, so don't worry if you feel you don't have a full solution. Because in practice, we only need to master the projection method, and the mathematical meaning can be gradually comprehended.
By definition, after determining f(n), we can get the time complexity O(f(n)). So how to determine the asymptotic upper bound f(n)? The overall is divided into two steps: first count the number of operations, and then determine the asymptotic upper bound.
The First Step: Counting The Number Of Operations
For the code, it is sufficient to calculate from top to bottom line by line. However, since the constant term c \cdot f(n) in the above c \cdot f(n) can take any size, the various coefficients and constant terms in the number of operations T(n) can be ignored. Based on this principle, the following counting simplification techniques can be summarized.
- Ignore the constant terms in $T(n)$. Since none of them are related to
n, they have no effect on the time complexity. - omits all coefficients. For example, loops
2ntimes,5n + 1times, etc., can be simplified and notated asntimes because the coefficients beforenhave no effect on the time complexity. - Use multiplication when loops are nested. The total number of operations is equal to the product of the number of operations of the outer and inner levels of the loop, and each level of the loop can still be nested by applying the techniques in points
1.and2.respectively.
Given a function, we can use the above trick to count the number of operations.
=== "Python"
```python title=""
def algorithm(n: int):
a = 1 # +0 (trick 1)
a = a + n # +0 (trick 1)
# +n (technique 2)
for i in range(5 * n + 1):
print(0)
# +n*n (technique 3)
for i in range(2 * n):
for j in range(n + 1):
print(0)
```
=== "C++"
```cpp title=""
void algorithm(int n) {
int a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for (int i = 0; i < 5 * n + 1; i++) {
cout << 0 << endl;
}
// +n*n (technique 3)
for (int i = 0; i < 2 * n; i++) {
for (int j = 0; j < n + 1; j++) {
cout << 0 << endl;
}
}
}
```
=== "Java"
```java title=""
void algorithm(int n) {
int a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for (int i = 0; i < 5 * n + 1; i++) {
System.out.println(0);
}
// +n*n (technique 3)
for (int i = 0; i < 2 * n; i++) {
for (int j = 0; j < n + 1; j++) {
System.out.println(0);
}
}
}
```
=== "C#"
```csharp title=""
void Algorithm(int n) {
int a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for (int i = 0; i < 5 * n + 1; i++) {
Console.WriteLine(0);
}
// +n*n (technique 3)
for (int i = 0; i < 2 * n; i++) {
for (int j = 0; j < n + 1; j++) {
Console.WriteLine(0);
}
}
}
```
=== "Go"
```go title=""
func algorithm(n int) {
a := 1 // +0 (trick 1)
a = a + n // +0 (trick 1)
// +n (technique 2)
for i := 0; i < 5 * n + 1; i++ {
fmt.Println(0)
}
// +n*n (technique 3)
for i := 0; i < 2 * n; i++ {
for j := 0; j < n + 1; j++ {
fmt.Println(0)
}
}
}
```
=== "Swift"
```swift title=""
func algorithm(n: Int) {
var a = 1 // +0 (trick 1)
a = a + n // +0 (trick 1)
// +n (technique 2)
for _ in 0 ..< (5 * n + 1) {
print(0)
}
// +n*n (technique 3)
for _ in 0 ..< (2 * n) {
for _ in 0 ..< (n + 1) {
print(0)
}
}
}
```
=== "JS"
```javascript title=""
function algorithm(n) {
let a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for (let i = 0; i < 5 * n + 1; i++) {
console.log(0);
}
// +n*n (technique 3)
for (let i = 0; i < 2 * n; i++) {
for (let j = 0; j < n + 1; j++) {
console.log(0);
}
}
}
```
=== "TS"
```typescript title=""
function algorithm(n: number): void {
let a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for (let i = 0; i < 5 * n + 1; i++) {
console.log(0);
}
// +n*n (technique 3)
for (let i = 0; i < 2 * n; i++) {
for (let j = 0; j < n + 1; j++) {
console.log(0);
}
}
}
```
=== "Dart"
```dart title=""
void algorithm(int n) {
int a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for (int i = 0; i < 5 * n + 1; i++) {
print(0);
}
// +n*n (technique 3)
for (int i = 0; i < 2 * n; i++) {
for (int j = 0; j < n + 1; j++) {
print(0);
}
}
}
```
=== "Rust"
```rust title=""
fn algorithm(n: i32) {
let mut a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for i in 0..(5 * n + 1) {
println!("{}", 0);
}
// +n*n (technique 3)
for i in 0..(2 * n) {
for j in 0..(n + 1) {
println!("{}", 0);
}
}
}
```
=== "C"
```c title=""
void algorithm(int n) {
int a = 1; // +0 (trick 1)
a = a + n; // +0 (trick 1)
// +n (technique 2)
for (int i = 0; i < 5 * n + 1; i++) {
printf("%d", 0);
}
// +n*n (technique 3)
for (int i = 0; i < 2 * n; i++) {
for (int j = 0; j < n + 1; j++) {
printf("%d", 0);
}
}
}
```
=== "Zig"
```zig title=""
fn algorithm(n: usize) void {
var a: i32 = 1; // +0 (trick 1)
a = a + @as(i32, @intCast(n)); // +0 (trick 1)
// +n (technique 2)
for(0..(5 * n + 1)) |_| {
std.debug.print("{}\n", .{0});
}
// +n*n (technique 3)
for(0..(2 * n)) |_| {
for(0..(n + 1)) |_| {
std.debug.print("{}\n", .{0});
}
}
}
```
The following equations show the statistical results before and after using the above technique, both of which were introduced with a time complexity of O(n^2) .
$$
\begin{aligned}
T(n) & = 2n(n + 1) + (5n + 1) + 2 & \text{complete statistics (-.-|||)} \newline
& = 2n^2 + 7n + 3 \newline
T(n) & = n^2 + n & \text{Lazy Stats (o.O)}
\end{aligned}
Step 2: Judging The Asymptotic Upper Bounds
The time complexity is determined by the highest order term in the polynomial $T(n)$. This is because as n tends to infinity, the highest order term will play a dominant role and the effects of all other terms can be ignored.
The table below shows some examples, some of which have exaggerated values to emphasize the conclusion that "the coefficients can't touch the order". As n tends to infinity, these constants become irrelevant.
Table Time complexity corresponding to different number of operations
number of operations T(n) |
time complexity O(f(n)) |
|---|---|
100000 |
O(1) |
3n + 2 |
O(n) |
2n^2 + 3n + 2 |
O(n^2) |
n^3 + 10000n^2 |
O(n^3) |
2^n + 10000n^{10000} |
O(2^n) |
Common Types
Let the input data size be n , the common types of time complexity are shown in the figure below (in descending order).
$$
\begin{aligned}
O(1) < O(\log n) < O(n) < O(n \log n) < O(n^2) < O(2^n) < O(n!) \newline
\text{constant order} < \text{logarithmic order} < \text{linear order} < \text{linear logarithmic order} < \text{square order} < \text{exponential order} < \text{multiplication order}
\end{aligned}

Constant Order O(1)
The number of operations of the constant order is independent of the input data size n, i.e., it does not change with n.
In the following function, although the number of operations size may be large, the time complexity is still O(1) because it is independent of the input data size n :
[file]{time_complexity}-[class]{}-[func]{constant}
Linear Order O(N)
The number of operations in a linear order grows in linear steps relative to the input data size n. Linear orders are usually found in single level loops:
[file]{time_complexity}-[class]{}-[func]{linear}
The time complexity of operations such as traversing an array and traversing a linked list is O(n) , where n is the length of the array or linked list:
[file]{time_complexity}-[class]{}-[func]{array_traversal}
It is worth noting that Input data size n needs to be determined specifically according to the type of input data. For example, in the first example, the variable n is the input data size; in the second example, the array length n is the data size.
Squared Order O(N^2)
The number of operations in the square order grows in square steps with respect to the size of the input data n. The squared order is usually found in nested loops, where both the outer and inner levels are O(n) and therefore overall O(n^2):
[file]{time_complexity}-[class]{}-[func]{quadratic}
The figure below compares the three time complexities of constant order, linear order and squared order.

Taking bubble sort as an example, the outer loop executes n - 1 times, and the inner loop executes n-1, n-2, \dots, 2, 1 times, which averages out to n / 2 times, resulting in a time complexity of O((n - 1) n / 2) = O(n^2) .
[file]{time_complexity}-[class]{}-[func]{bubble_sort}
Exponential Order O(2^N)
Cell division in biology is a typical example of exponential growth: the initial state is 1 cells, after one round of division it becomes 2, after two rounds of division it becomes 4, and so on, after n rounds of division there are 2^n cells.
The figure below and the following code simulate the process of cell division with a time complexity of O(2^n) .
[file]{time_complexity}-[class]{}-[func]{exponential}
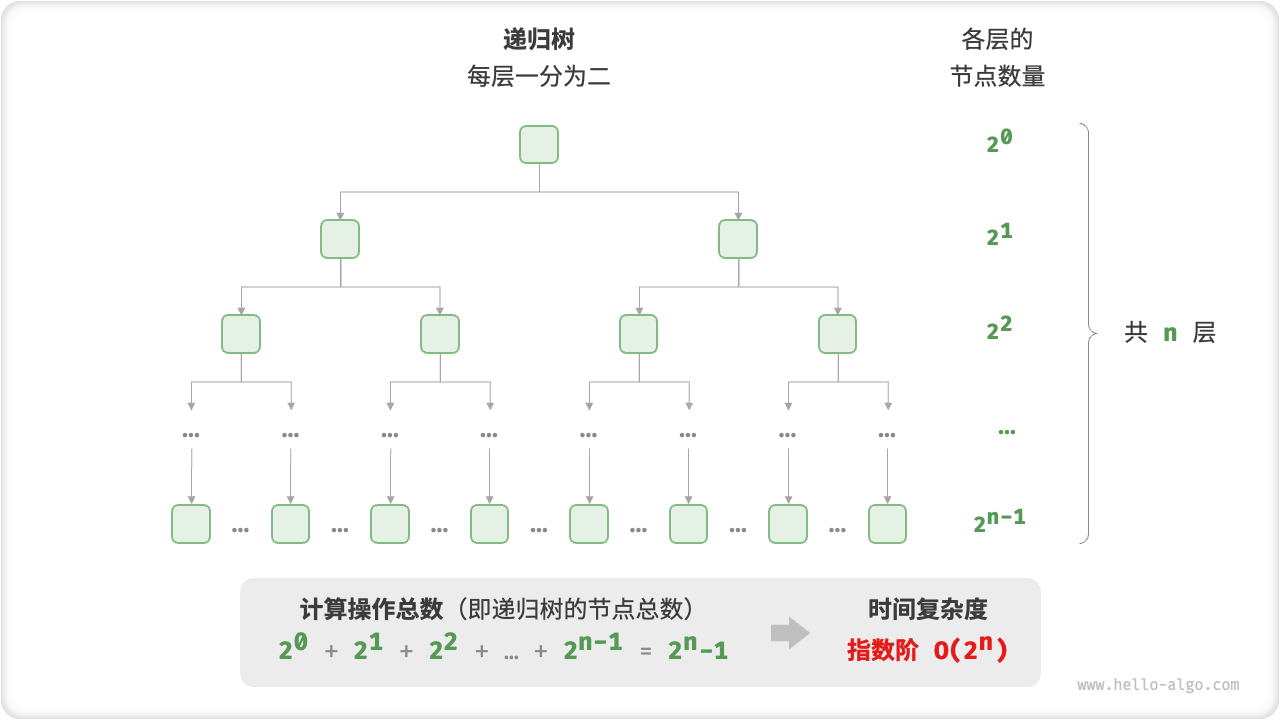
In practical algorithms, exponential orders are often found in recursion functions. For example, in the following code, it recursively splits in two and stops after n splits:
[file]{time_complexity}-[class]{}-[func]{exp_recur}
Exponential order grows very rapidly and is more common in exhaustive methods (brute force search, backtracking, etc.). For problems with large data sizes, exponential order is unacceptable and usually requires the use of algorithms such as dynamic programming or greedy algorithms to solve.
Logarithmic Order O(\Log N)
In contrast to the exponential order, the logarithmic order reflects the "each round is reduced to half" case. Let the input data size be n, and since each round is reduced to half, the number of loops is \log_2 n, which is the inverse function of 2^n.
The figure below and the code below simulate the process of "reducing each round to half" with a time complexity of O(\log_2 n), which is abbreviated as O(\log n).
[file]{time_complexity}-[class]{}-[func]{logarithmic}
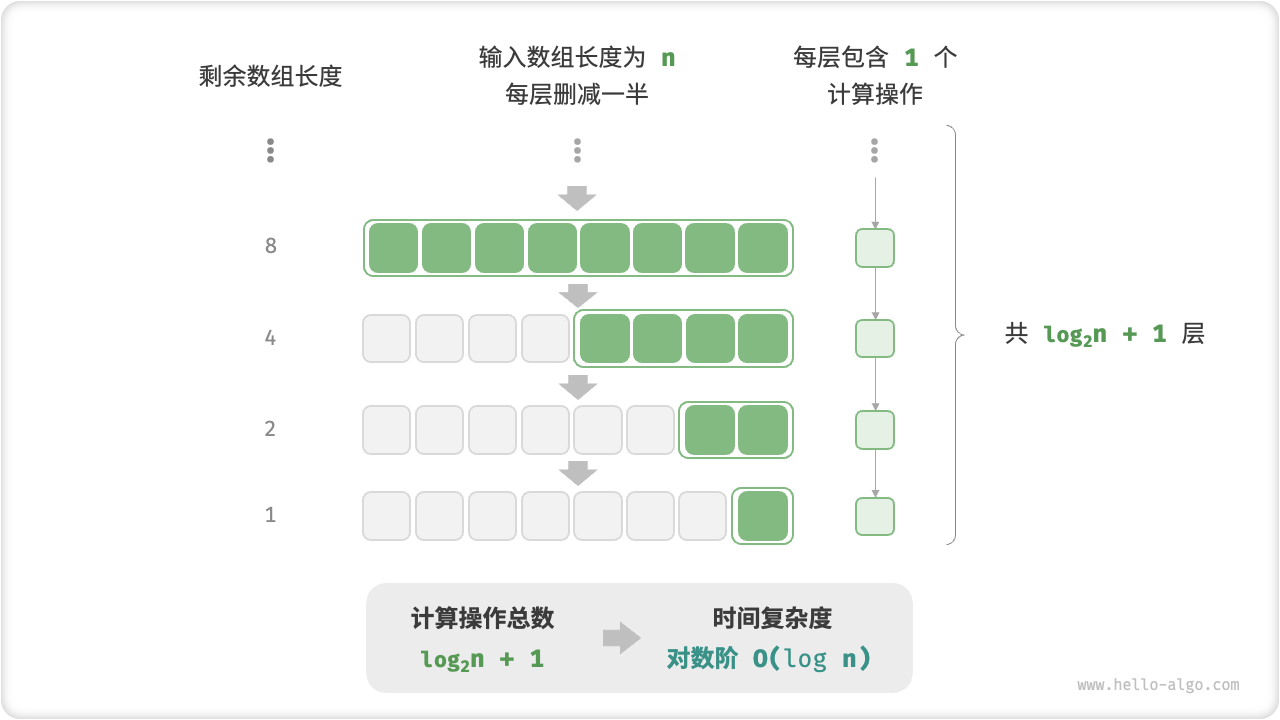
Similar to the exponential order, the logarithmic order is often found in recursion functions. The following code forms a recursion tree of height \log_2 n:
[file]{time_complexity}-[class]{}-[func]{log_recur}
Logarithmic order is often found in algorithms based on the divide and conquer strategy, which reflects the algorithmic ideas of "dividing one into many" and "simplifying the complexity into simplicity". It grows slowly and is the second most desirable time complexity after constant order.
!!! tip "What is the base of O(\log n)?"
To be precise, the corresponding time complexity of "one divided into $m$" is $O(\log_m n)$ . And by using the logarithmic permutation formula, we can get equal time complexity with different bases:
$$
O(\log_m n) = O(\log_k n / \log_k m) = O(\log_k n)
$$
That is, the base $m$ can be converted without affecting the complexity. Therefore we usually omit the base $m$ and write the logarithmic order directly as $O(\log n)$.
Linear Logarithmic Order O(N \Log N)
The linear logarithmic order is often found in nested loops, and the time complexity of the two levels of loops is O(\log n) and O(n) respectively. The related code is as follows:
[file]{time_complexity}-[class]{}-[func]{linear_log_recur}
The figure below shows how the linear logarithmic order is generated. The total number of operations at each level of the binary tree is n , and the tree has a total of \log_2 n + 1 levels, resulting in a time complexity of O(n\log n) .

Mainstream sorting algorithms typically have a time complexity of O(n \log n) , such as quick sort, merge sort, heap sort, etc.
The Factorial Order O(N!)
The factorial order corresponds to the mathematical "permutations problem". Given n elements that do not repeat each other, find all possible permutations of them, the number of permutations being:
$$
n! = n \times (n - 1) \times (n - 2) \times \dots \times 2 \times 1
Factorials are usually implemented using recursion. As shown in the figure below and in the code below, the first level splits n, the second level splits n - 1, and so on, until the splitting stops at the $n$th level:
[file]{time_complexity}-[class]{}-[func]{factorial_recur}

Note that since there is always n! > 2^n when n \geq 4, the factorial order grows faster than the exponential order, and is also unacceptable when n is large.
Worst, Best, Average Time Complexity
The time efficiency of algorithms is often not fixed, but is related to the distribution of the input data. Suppose an array nums of length n is input, where nums consists of numbers from 1 to n, each of which occurs only once; however, the order of the elements is randomly upset, and the goal of the task is to return the index of element 1. We can draw the following conclusion.
- When
nums = [? , ? , ... , 1], i.e., when the end element is1, a complete traversal of the array is required, to reach the worst time complexity $O(n)$ . - When
nums = [1, ? , ? , ...], i.e., when the first element is1, there is no need to continue traversing the array no matter how long it is, reaching the optimal time complexity $\Omega(1)$ .
The "worst time complexity" corresponds to the asymptotic upper bound of the function and is denoted by the large O notation. Correspondingly, the "optimal time complexity" corresponds to the asymptotic lower bound of the function and is denoted in \Omega notation:
[file]{worst_best_time_complexity}-[class]{}-[func]{find_one}
It is worth stating that we rarely use the optimal time complexity in practice because it is usually only attainable with a small probability and may be somewhat misleading. whereas the worst time complexity is more practical because it gives a safe value for efficiency and allows us to use the algorithm with confidence.
From the above examples, it can be seen that the worst or best time complexity only occurs in "special data distributions", and the probability of these cases may be very small, which does not truly reflect the efficiency of the algorithm. In contrast, the average time complexity of can reflect the efficiency of the algorithm under random input data, which is denoted by the \Theta notation.
For some algorithms, we can simply derive the average case under a random data distribution. For example, in the above example, since the input array is scrambled, the probability of an element 1 appearing at any index is equal, so the average number of loops of the algorithm is half of the length of the array n / 2 , and the average time complexity is \Theta(n / 2) = \Theta(n) .
However, for more complex algorithms, calculating the average time complexity is often difficult because it is hard to analyze the overall mathematical expectation given the data distribution. In this case, we usually use the worst time complexity as a criterion for the efficiency of the algorithm.
!!! question "Why do you rarely see the \Theta symbol?"
Perhaps because the $O$ symbol is so catchy, we often use it to denote average time complexity. However, this practice is not standardized in the strict sense. In this book and other sources, if you encounter a statement like "average time complexity $O(n)$", please understand it as $\Theta(n)$.