mirror of
https://github.com/krahets/hello-algo.git
synced 2024-12-25 14:36:29 +08:00
* Sync recent changes to the revised Word. * Revised the preface chapter * Revised the introduction chapter * Revised the computation complexity chapter * Revised the chapter data structure * Revised the chapter array and linked list * Revised the chapter stack and queue * Revised the chapter hashing * Revised the chapter tree * Revised the chapter heap * Revised the chapter graph * Revised the chapter searching * Reivised the sorting chapter * Revised the divide and conquer chapter * Revised the chapter backtacking * Revised the DP chapter * Revised the greedy chapter * Revised the appendix chapter * Revised the preface chapter doubly * Revised the figures
2.6 KiB
2.6 KiB
Top-K 问题
!!! question
给定一个长度为 $n$ 的无序数组 `nums` ,请返回数组中前 $k$ 大的元素。
对于该问题,我们先介绍两种思路比较直接的解法,再介绍效率更高的堆解法。
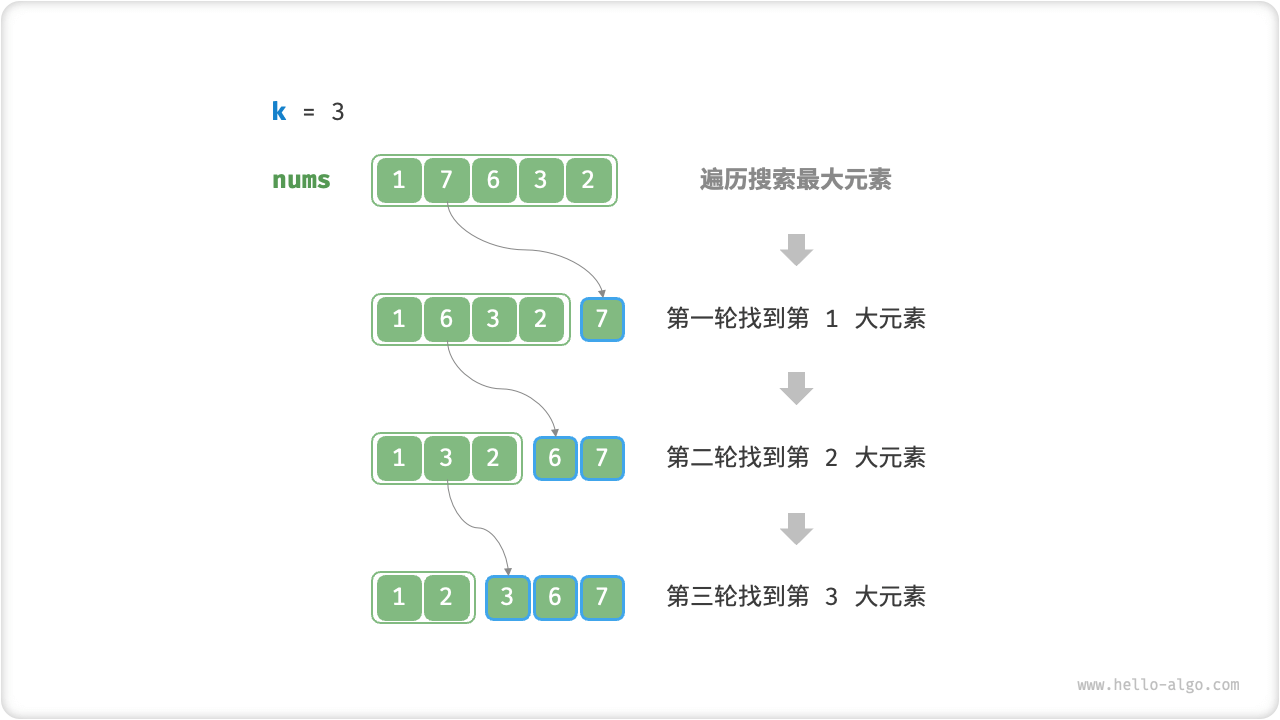
方法一:遍历选择
我们可以进行下图所示的 k 轮遍历,分别在每轮中提取第 $1$、$2$、$\dots$、k 大的元素,时间复杂度为 O(nk) 。
此方法只适用于 k \ll n 的情况,因为当 k 与 n 比较接近时,其时间复杂度趋向于 O(n^2) ,非常耗时。
!!! tip
当 $k = n$ 时,我们可以得到完整的有序序列,此时等价于“选择排序”算法。
方法二:排序
如下图所示,我们可以先对数组 nums 进行排序,再返回最右边的 k 个元素,时间复杂度为 O(n \log n) 。
显然,该方法“超额”完成任务了,因为我们只需找出最大的 k 个元素即可,而不需要排序其他元素。

方法三:堆
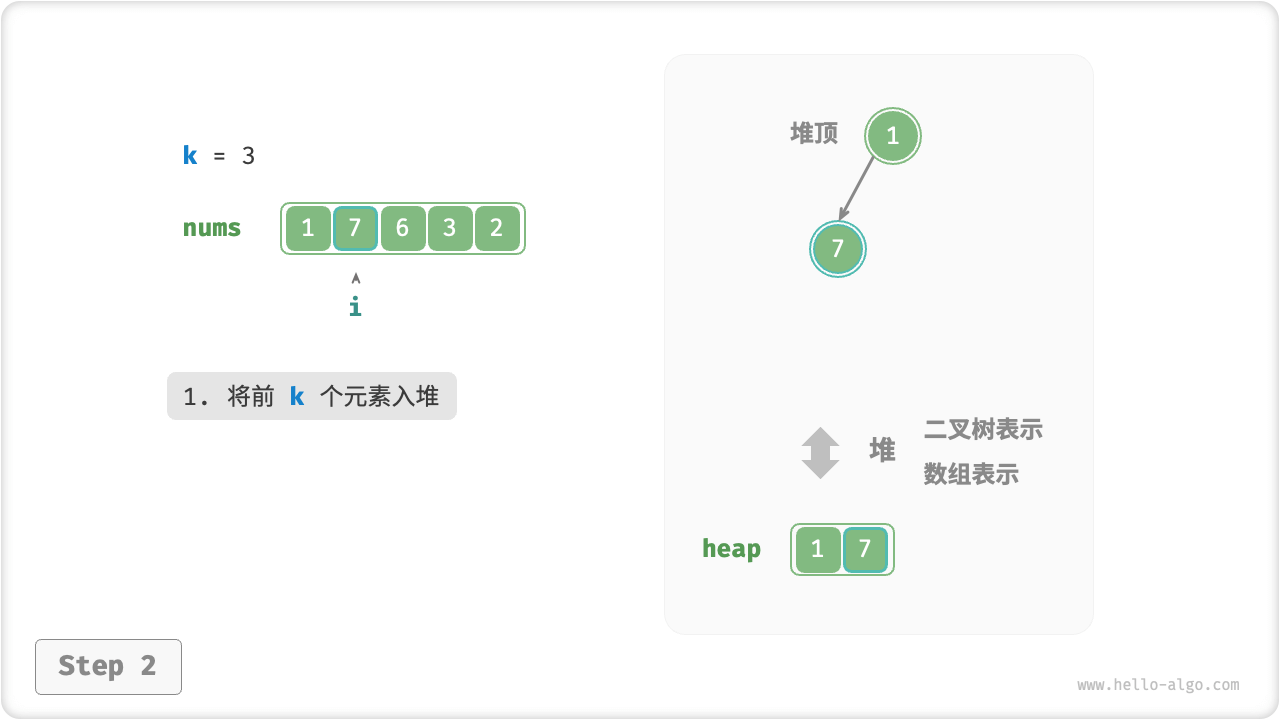
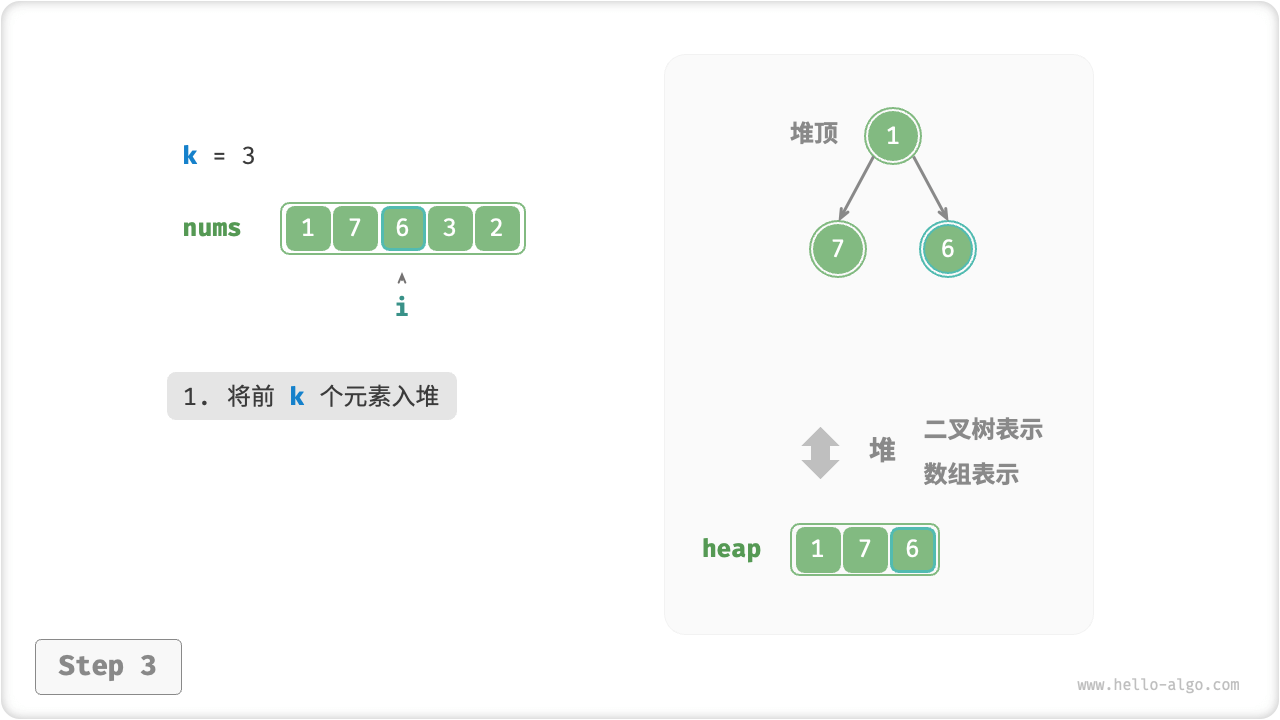
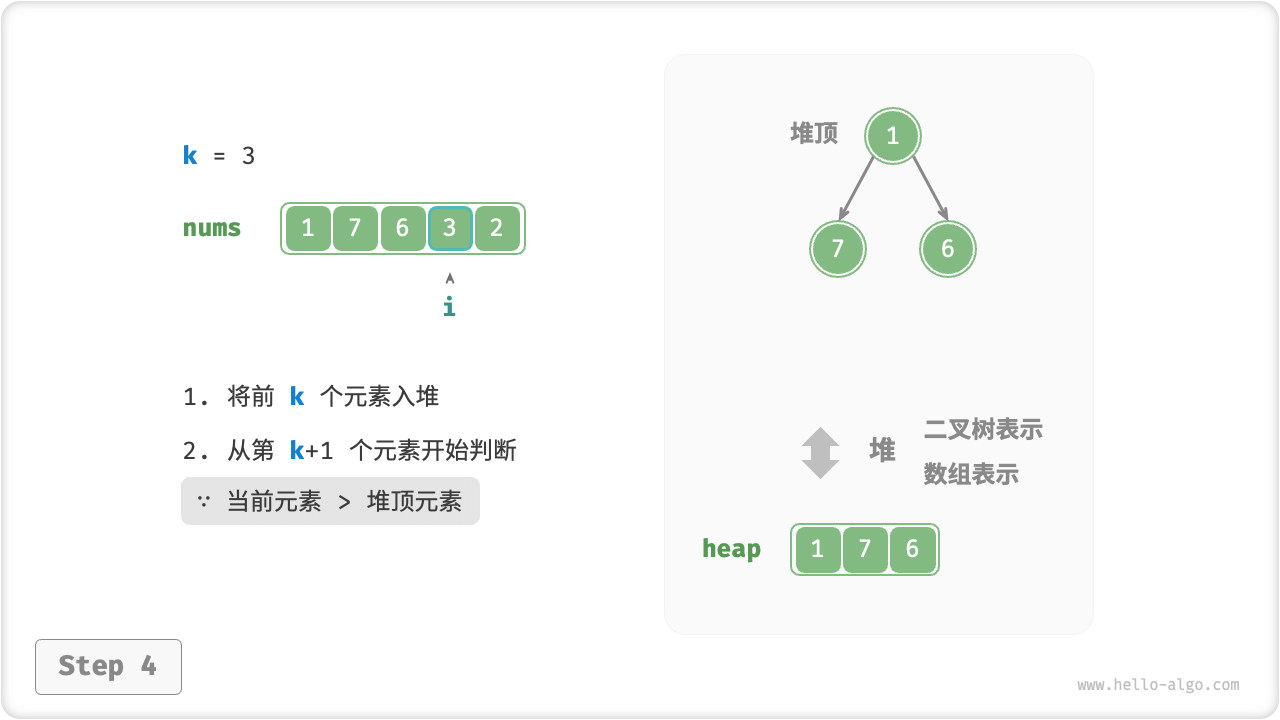
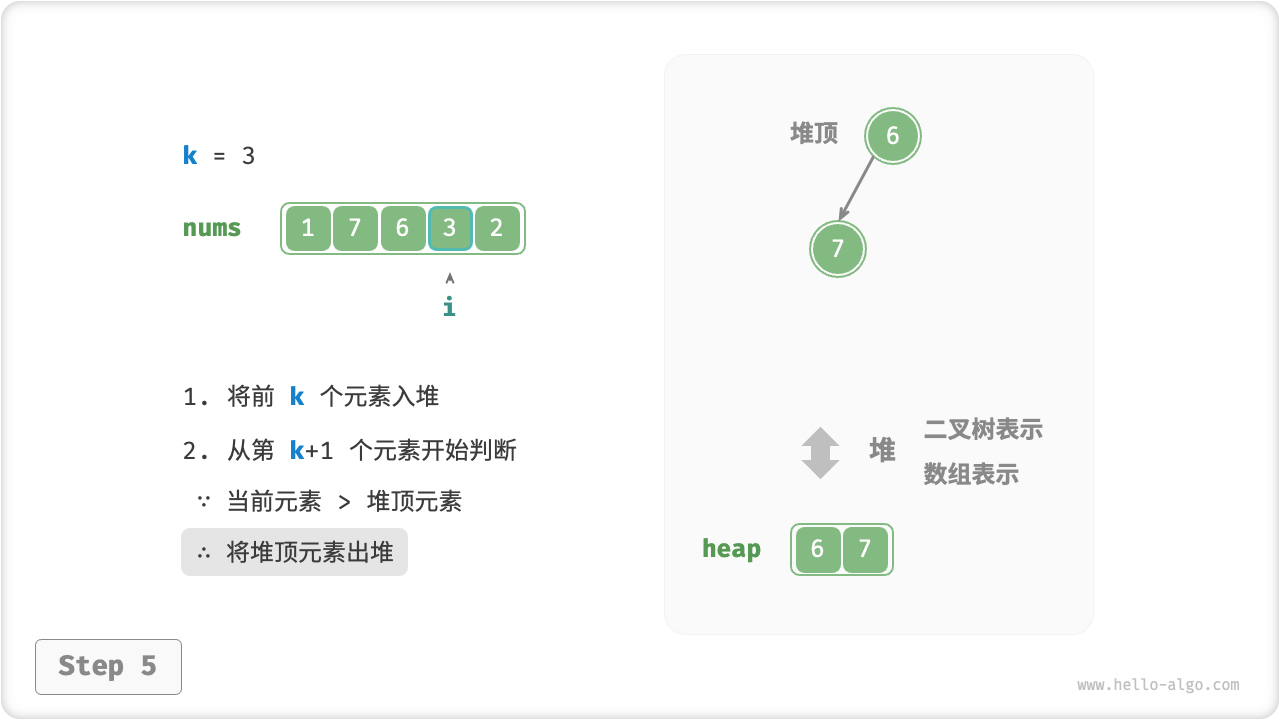
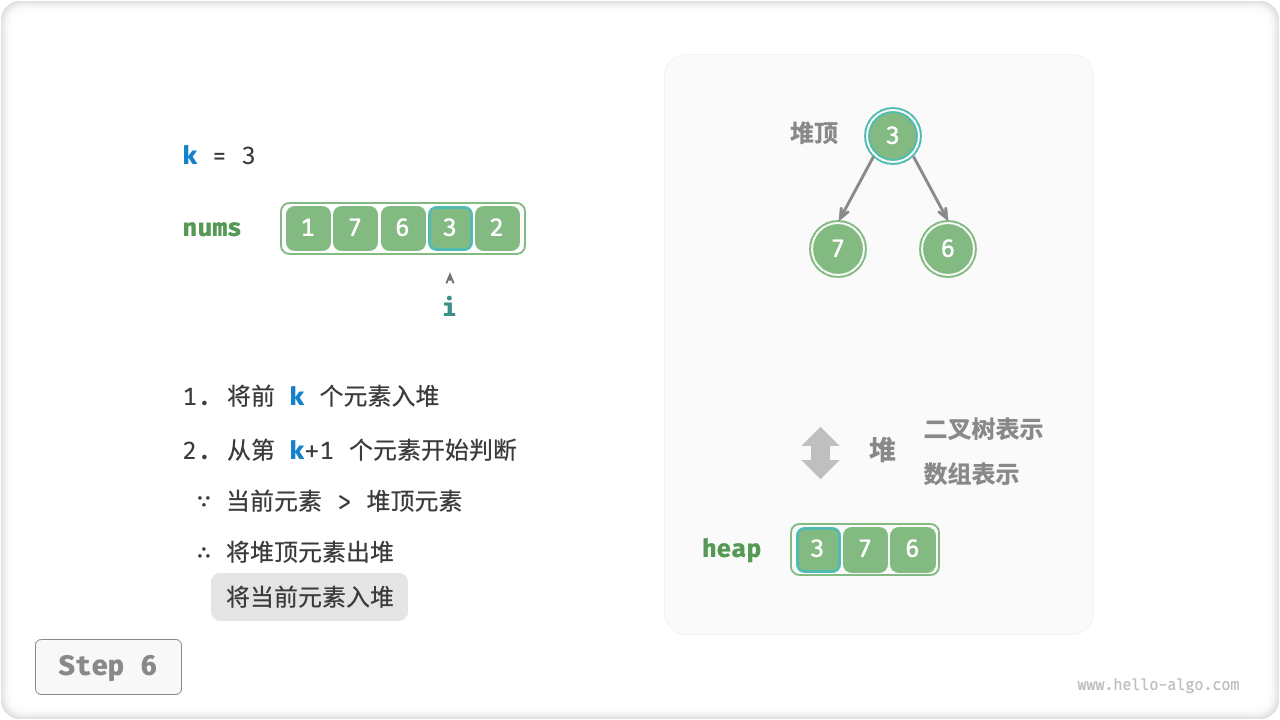
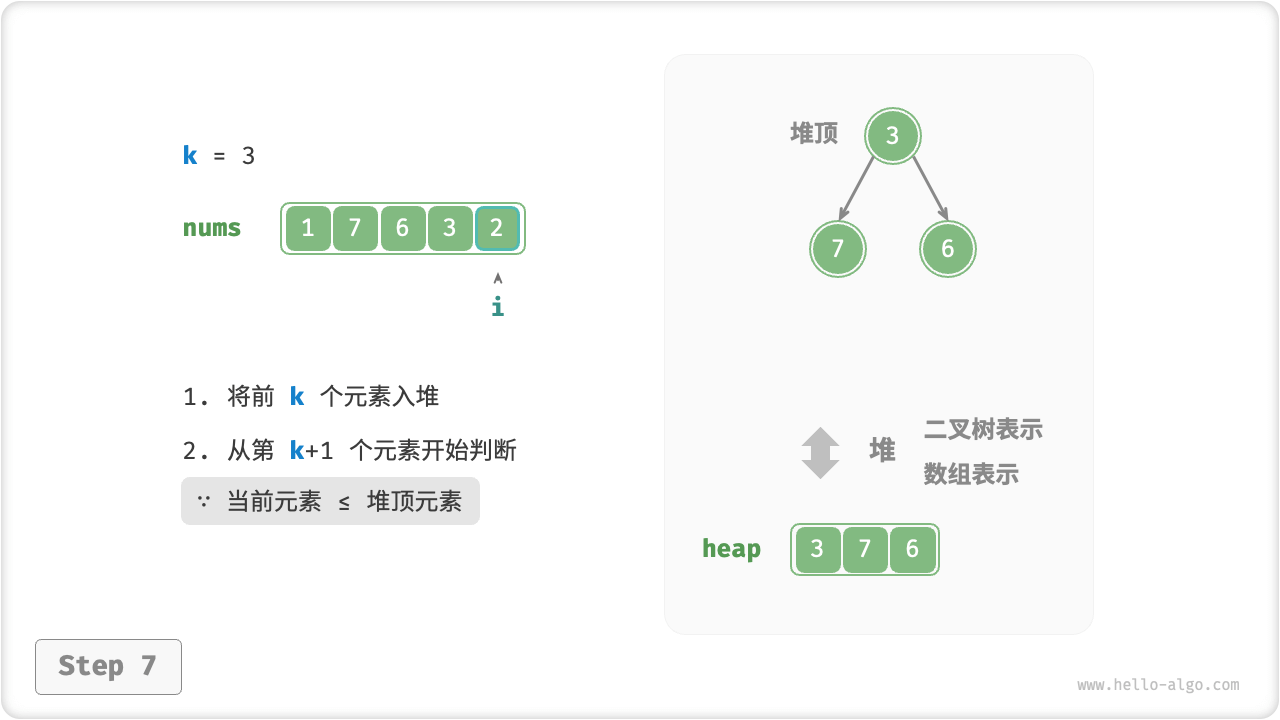
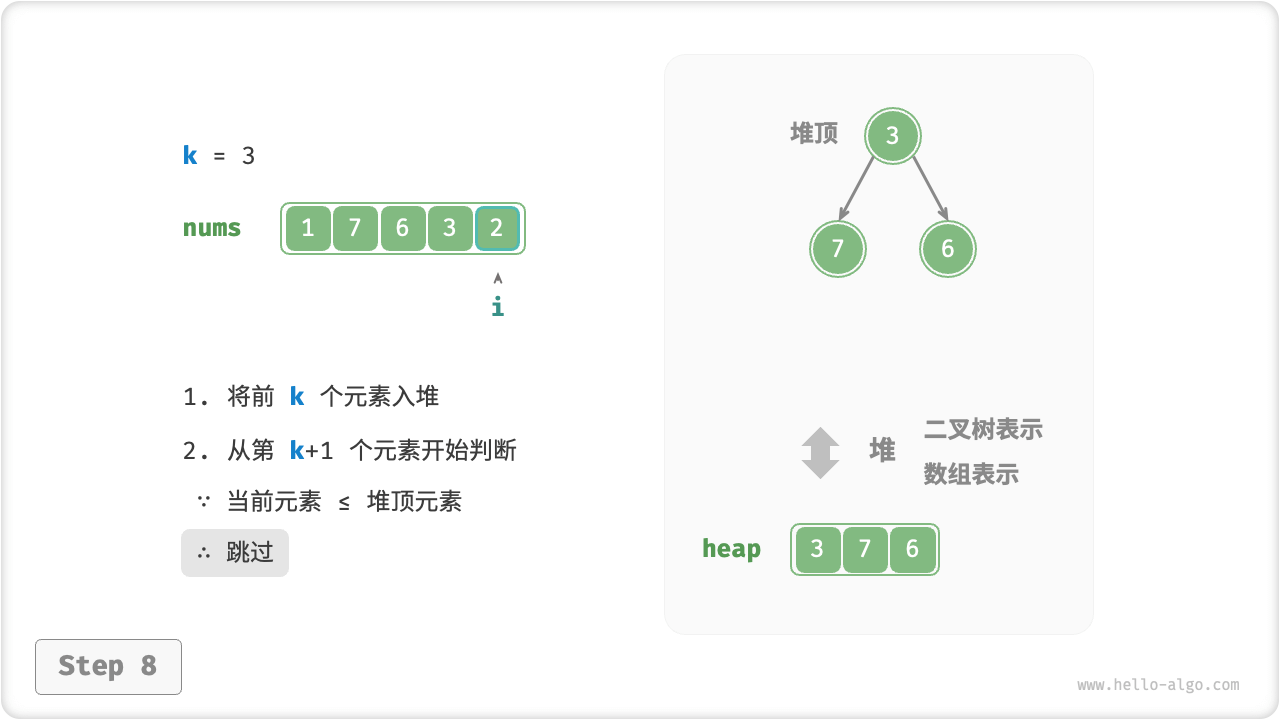
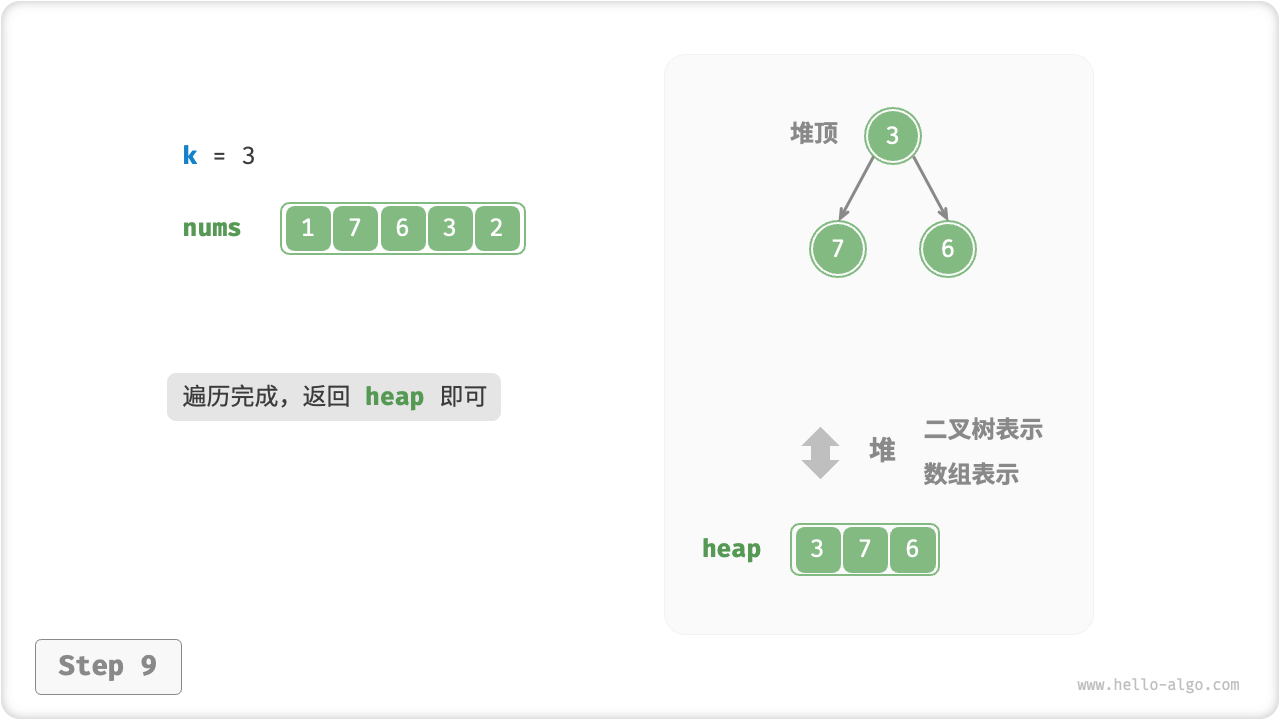
我们可以基于堆更加高效地解决 Top-K 问题,流程如下图所示。
- 初始化一个小顶堆,其堆顶元素最小。
- 先将数组的前
k个元素依次入堆。 - 从第
k + 1个元素开始,若当前元素大于堆顶元素,则将堆顶元素出堆,并将当前元素入堆。 - 遍历完成后,堆中保存的就是最大的
k个元素。
=== "<1>"

=== "<2>"
=== "<3>"
=== "<4>"
=== "<5>"
=== "<6>"
=== "<7>"
=== "<8>"
=== "<9>"
示例代码如下:
[file]{top_k}-[class]{}-[func]{top_k_heap}
总共执行了 n 轮入堆和出堆,堆的最大长度为 k ,因此时间复杂度为 O(n \log k) 。该方法的效率很高,当 k 较小时,时间复杂度趋向 O(n) ;当 k 较大时,时间复杂度不会超过 O(n \log n) 。
另外,该方法适用于动态数据流的使用场景。在不断加入数据时,我们可以持续维护堆内的元素,从而实现最大 k 个元素的动态更新。