2.3 時間複雜度¶
執行時間可以直觀且準確地反映演算法的效率。如果我們想準確預估一段程式碼的執行時間,應該如何操作呢?
- 確定執行平臺,包括硬體配置、程式語言、系統環境等,這些因素都會影響程式碼的執行效率。
- 評估各種計算操作所需的執行時間,例如加法操作
+需要 1 ns ,乘法操作*需要 10 ns ,列印操作print()需要 5 ns 等。 - 統計程式碼中所有的計算操作,並將所有操作的執行時間求和,從而得到執行時間。
例如在以下程式碼中,輸入資料大小為 \(n\) :
根據以上方法,可以得到演算法的執行時間為 \((6n + 12)\) ns :
但實際上,統計演算法的執行時間既不合理也不現實。首先,我們不希望將預估時間和執行平臺繫結,因為演算法需要在各種不同的平臺上執行。其次,我們很難獲知每種操作的執行時間,這給預估過程帶來了極大的難度。
2.3.1 統計時間增長趨勢¶
時間複雜度分析統計的不是演算法執行時間,而是演算法執行時間隨著資料量變大時的增長趨勢。
“時間增長趨勢”這個概念比較抽象,我們透過一個例子來加以理解。假設輸入資料大小為 \(n\) ,給定三個演算法 A、B 和 C :
// 演算法 A 的時間複雜度:常數階
function algorithm_A(n: number): void {
console.log(0);
}
// 演算法 B 的時間複雜度:線性階
function algorithm_B(n: number): void {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// 演算法 C 的時間複雜度:常數階
function algorithm_C(n: number): void {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
// 演算法 A 的時間複雜度:常數階
fn algorithm_A(n: usize) void {
_ = n;
std.debug.print("{}\n", .{0});
}
// 演算法 B 的時間複雜度:線性階
fn algorithm_B(n: i32) void {
for (0..n) |_| {
std.debug.print("{}\n", .{0});
}
}
// 演算法 C 的時間複雜度:常數階
fn algorithm_C(n: i32) void {
_ = n;
for (0..1000000) |_| {
std.debug.print("{}\n", .{0});
}
}
圖 2-7 展示了以上三個演算法函式的時間複雜度。
- 演算法
A只有 \(1\) 個列印操作,演算法執行時間不隨著 \(n\) 增大而增長。我們稱此演算法的時間複雜度為“常數階”。 - 演算法
B中的列印操作需要迴圈 \(n\) 次,演算法執行時間隨著 \(n\) 增大呈線性增長。此演算法的時間複雜度被稱為“線性階”。 - 演算法
C中的列印操作需要迴圈 \(1000000\) 次,雖然執行時間很長,但它與輸入資料大小 \(n\) 無關。因此C的時間複雜度和A相同,仍為“常數階”。

圖 2-7 演算法 A、B 和 C 的時間增長趨勢
相較於直接統計演算法的執行時間,時間複雜度分析有哪些特點呢?
- 時間複雜度能夠有效評估演算法效率。例如,演算法
B的執行時間呈線性增長,在 \(n > 1\) 時比演算法A更慢,在 \(n > 1000000\) 時比演算法C更慢。事實上,只要輸入資料大小 \(n\) 足夠大,複雜度為“常數階”的演算法一定優於“線性階”的演算法,這正是時間增長趨勢的含義。 - 時間複雜度的推算方法更簡便。顯然,執行平臺和計算操作型別都與演算法執行時間的增長趨勢無關。因此在時間複雜度分析中,我們可以簡單地將所有計算操作的執行時間視為相同的“單位時間”,從而將“計算操作執行時間統計”簡化為“計算操作數量統計”,這樣一來估算難度就大大降低了。
- 時間複雜度也存在一定的侷限性。例如,儘管演算法
A和C的時間複雜度相同,但實際執行時間差別很大。同樣,儘管演算法B的時間複雜度比C高,但在輸入資料大小 \(n\) 較小時,演算法B明顯優於演算法C。在這些情況下,我們很難僅憑時間複雜度判斷演算法效率的高低。當然,儘管存在上述問題,複雜度分析仍然是評判演算法效率最有效且常用的方法。
2.3.2 函式漸近上界¶
給定一個輸入大小為 \(n\) 的函式:
設演算法的操作數量是一個關於輸入資料大小 \(n\) 的函式,記為 \(T(n)\) ,則以上函式的操作數量為:
\(T(n)\) 是一次函式,說明其執行時間的增長趨勢是線性的,因此它的時間複雜度是線性階。
我們將線性階的時間複雜度記為 \(O(n)\) ,這個數學符號稱為大 \(O\) 記號(big-\(O\) notation),表示函式 \(T(n)\) 的漸近上界(asymptotic upper bound)。
時間複雜度分析本質上是計算“操作數量 \(T(n)\)”的漸近上界,它具有明確的數學定義。
函式漸近上界
若存在正實數 \(c\) 和實數 \(n_0\) ,使得對於所有的 \(n > n_0\) ,均有 \(T(n) \leq c \cdot f(n)\) ,則可認為 \(f(n)\) 給出了 \(T(n)\) 的一個漸近上界,記為 \(T(n) = O(f(n))\) 。
如圖 2-8 所示,計算漸近上界就是尋找一個函式 \(f(n)\) ,使得當 \(n\) 趨向於無窮大時,\(T(n)\) 和 \(f(n)\) 處於相同的增長級別,僅相差一個常數項 \(c\) 的倍數。
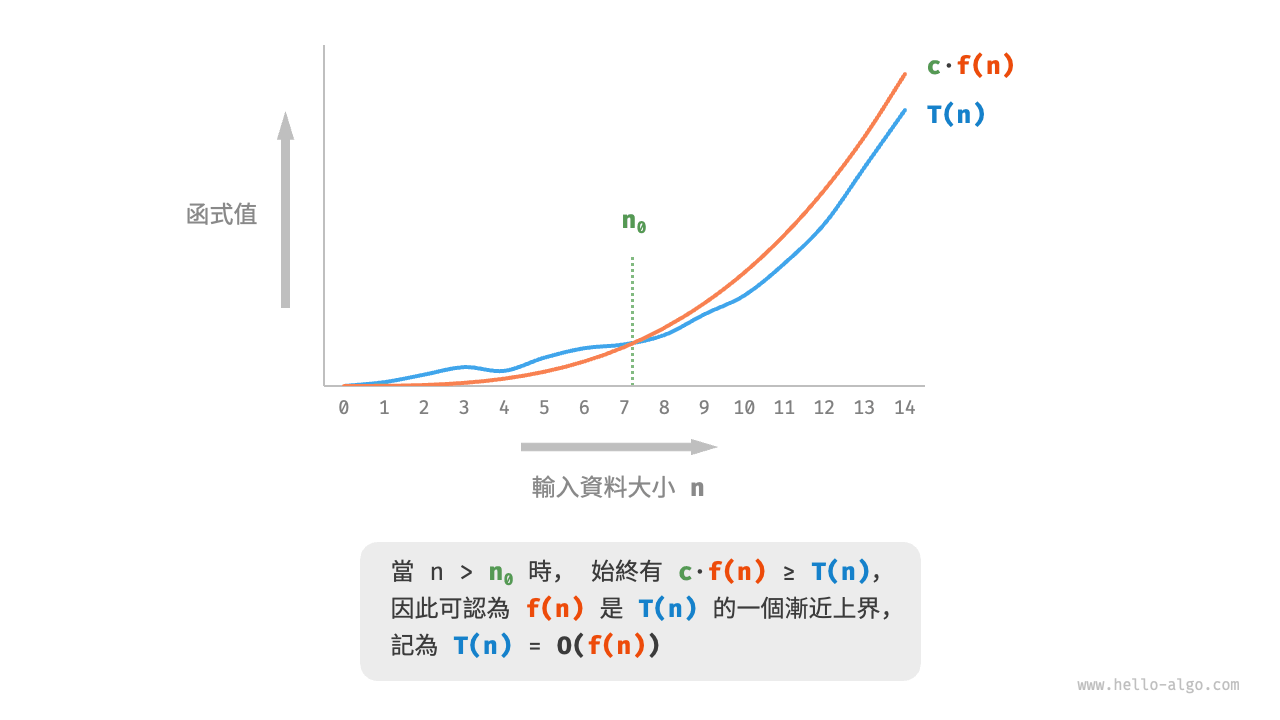
圖 2-8 函式的漸近上界
2.3.3 推算方法¶
漸近上界的數學味兒有點重,如果你感覺沒有完全理解,也無須擔心。我們可以先掌握推算方法,在不斷的實踐中,就可以逐漸領悟其數學意義。
根據定義,確定 \(f(n)\) 之後,我們便可得到時間複雜度 \(O(f(n))\) 。那麼如何確定漸近上界 \(f(n)\) 呢?總體分為兩步:首先統計操作數量,然後判斷漸近上界。
1. 第一步:統計操作數量¶
針對程式碼,逐行從上到下計算即可。然而,由於上述 \(c \cdot f(n)\) 中的常數項 \(c\) 可以取任意大小,因此操作數量 \(T(n)\) 中的各種係數、常數項都可以忽略。根據此原則,可以總結出以下計數簡化技巧。
- 忽略 \(T(n)\) 中的常數項。因為它們都與 \(n\) 無關,所以對時間複雜度不產生影響。
- 省略所有係數。例如,迴圈 \(2n\) 次、\(5n + 1\) 次等,都可以簡化記為 \(n\) 次,因為 \(n\) 前面的係數對時間複雜度沒有影響。
- 迴圈巢狀時使用乘法。總操作數量等於外層迴圈和內層迴圈操作數量之積,每一層迴圈依然可以分別套用第
1.點和第2.點的技巧。
給定一個函式,我們可以用上述技巧來統計操作數量:
以下公式展示了使用上述技巧前後的統計結果,兩者推算出的時間複雜度都為 \(O(n^2)\) 。
2. 第二步:判斷漸近上界¶
時間複雜度由 \(T(n)\) 中最高階的項來決定。這是因為在 \(n\) 趨於無窮大時,最高階的項將發揮主導作用,其他項的影響都可以忽略。
表 2-2 展示了一些例子,其中一些誇張的值是為了強調“係數無法撼動階數”這一結論。當 \(n\) 趨於無窮大時,這些常數變得無足輕重。
表 2-2 不同操作數量對應的時間複雜度
| 操作數量 \(T(n)\) | 時間複雜度 \(O(f(n))\) |
|---|---|
| \(100000\) | \(O(1)\) |
| \(3n + 2\) | \(O(n)\) |
| \(2n^2 + 3n + 2\) | \(O(n^2)\) |
| \(n^3 + 10000n^2\) | \(O(n^3)\) |
| \(2^n + 10000n^{10000}\) | \(O(2^n)\) |
2.3.4 常見型別¶
設輸入資料大小為 \(n\) ,常見的時間複雜度型別如圖 2-9 所示(按照從低到高的順序排列)。

圖 2-9 常見的時間複雜度型別
1. 常數階 \(O(1)\)¶
常數階的操作數量與輸入資料大小 \(n\) 無關,即不隨著 \(n\) 的變化而變化。
在以下函式中,儘管操作數量 size 可能很大,但由於其與輸入資料大小 \(n\) 無關,因此時間複雜度仍為 \(O(1)\) :
視覺化執行
2. 線性階 \(O(n)\)¶
線性階的操作數量相對於輸入資料大小 \(n\) 以線性級別增長。線性階通常出現在單層迴圈中:
視覺化執行
走訪陣列和走訪鏈結串列等操作的時間複雜度均為 \(O(n)\) ,其中 \(n\) 為陣列或鏈結串列的長度:
視覺化執行
值得注意的是,輸入資料大小 \(n\) 需根據輸入資料的型別來具體確定。比如在第一個示例中,變數 \(n\) 為輸入資料大小;在第二個示例中,陣列長度 \(n\) 為資料大小。
3. 平方階 \(O(n^2)\)¶
平方階的操作數量相對於輸入資料大小 \(n\) 以平方級別增長。平方階通常出現在巢狀迴圈中,外層迴圈和內層迴圈的時間複雜度都為 \(O(n)\) ,因此總體的時間複雜度為 \(O(n^2)\) :
視覺化執行
圖 2-10 對比了常數階、線性階和平方階三種時間複雜度。

圖 2-10 常數階、線性階和平方階的時間複雜度
以泡沫排序為例,外層迴圈執行 \(n - 1\) 次,內層迴圈執行 \(n-1\)、\(n-2\)、\(\dots\)、\(2\)、\(1\) 次,平均為 \(n / 2\) 次,因此時間複雜度為 \(O((n - 1) n / 2) = O(n^2)\) :
def bubble_sort(nums: list[int]) -> int:
"""平方階(泡沫排序)"""
count = 0 # 計數器
# 外迴圈:未排序區間為 [0, i]
for i in range(len(nums) - 1, 0, -1):
# 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for j in range(i):
if nums[j] > nums[j + 1]:
# 交換 nums[j] 與 nums[j + 1]
tmp: int = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 元素交換包含 3 個單元操作
return count
/* 平方階(泡沫排序) */
int bubbleSort(vector<int> &nums) {
int count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for (int i = nums.size() - 1; i > 0; i--) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
/* 平方階(泡沫排序) */
int bubbleSort(int[] nums) {
int count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for (int i = nums.length - 1; i > 0; i--) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
/* 平方階(泡沫排序) */
int BubbleSort(int[] nums) {
int count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for (int i = nums.Length - 1; i > 0; i--) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
(nums[j + 1], nums[j]) = (nums[j], nums[j + 1]);
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
/* 平方階(泡沫排序) */
func bubbleSort(nums []int) int {
count := 0 // 計數器
// 外迴圈:未排序區間為 [0, i]
for i := len(nums) - 1; i > 0; i-- {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for j := 0; j < i; j++ {
if nums[j] > nums[j+1] {
// 交換 nums[j] 與 nums[j + 1]
tmp := nums[j]
nums[j] = nums[j+1]
nums[j+1] = tmp
count += 3 // 元素交換包含 3 個單元操作
}
}
}
return count
}
/* 平方階(泡沫排序) */
func bubbleSort(nums: inout [Int]) -> Int {
var count = 0 // 計數器
// 外迴圈:未排序區間為 [0, i]
for i in nums.indices.dropFirst().reversed() {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for j in 0 ..< i {
if nums[j] > nums[j + 1] {
// 交換 nums[j] 與 nums[j + 1]
let tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 // 元素交換包含 3 個單元操作
}
}
}
return count
}
/* 平方階(泡沫排序) */
function bubbleSort(nums) {
let count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
/* 平方階(泡沫排序) */
function bubbleSort(nums: number[]): number {
let count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
/* 平方階(泡沫排序) */
int bubbleSort(List<int> nums) {
int count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for (var i = nums.length - 1; i > 0; i--) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (var j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
/* 平方階(泡沫排序) */
fn bubble_sort(nums: &mut [i32]) -> i32 {
let mut count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for i in (1..nums.len()).rev() {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for j in 0..i {
if nums[j] > nums[j + 1] {
// 交換 nums[j] 與 nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
count
}
/* 平方階(泡沫排序) */
int bubbleSort(int *nums, int n) {
int count = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
for (int i = n - 1; i > 0; i--) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
/* 平方階(泡沫排序) */
fun bubbleSort(nums: IntArray): Int {
var count = 0 // 計數器
// 外迴圈:未排序區間為 [0, i]
for (i in nums.size - 1 downTo 1) {
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for (j in 0..<i) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
val temp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = temp
count += 3 // 元素交換包含 3 個單元操作
}
}
}
return count
}
### 平方階(泡沫排序)###
def bubble_sort(nums)
count = 0 # 計數器
# 外迴圈:未排序區間為 [0, i]
for i in (nums.length - 1).downto(0)
# 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
for j in 0...i
if nums[j] > nums[j + 1]
# 交換 nums[j] 與 nums[j + 1]
tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 元素交換包含 3 個單元操作
end
end
end
count
end
// 平方階(泡沫排序)
fn bubbleSort(nums: []i32) i32 {
var count: i32 = 0; // 計數器
// 外迴圈:未排序區間為 [0, i]
var i: i32 = @as(i32, @intCast(nums.len)) - 1;
while (i > 0) : (i -= 1) {
var j: usize = 0;
// 內迴圈:將未排序區間 [0, i] 中的最大元素交換至該區間的最右端
while (j < i) : (j += 1) {
if (nums[j] > nums[j + 1]) {
// 交換 nums[j] 與 nums[j + 1]
var tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交換包含 3 個單元操作
}
}
}
return count;
}
視覺化執行
4. 指數階 \(O(2^n)\)¶
生物學的“細胞分裂”是指數階增長的典型例子:初始狀態為 \(1\) 個細胞,分裂一輪後變為 \(2\) 個,分裂兩輪後變為 \(4\) 個,以此類推,分裂 \(n\) 輪後有 \(2^n\) 個細胞。
圖 2-11 和以下程式碼模擬了細胞分裂的過程,時間複雜度為 \(O(2^n)\) :
// 指數階(迴圈實現)
fn exponential(n: i32) i32 {
var count: i32 = 0;
var bas: i32 = 1;
var i: i32 = 0;
// 細胞每輪一分為二,形成數列 1, 2, 4, 8, ..., 2^(n-1)
while (i < n) : (i += 1) {
var j: i32 = 0;
while (j < bas) : (j += 1) {
count += 1;
}
bas *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
視覺化執行
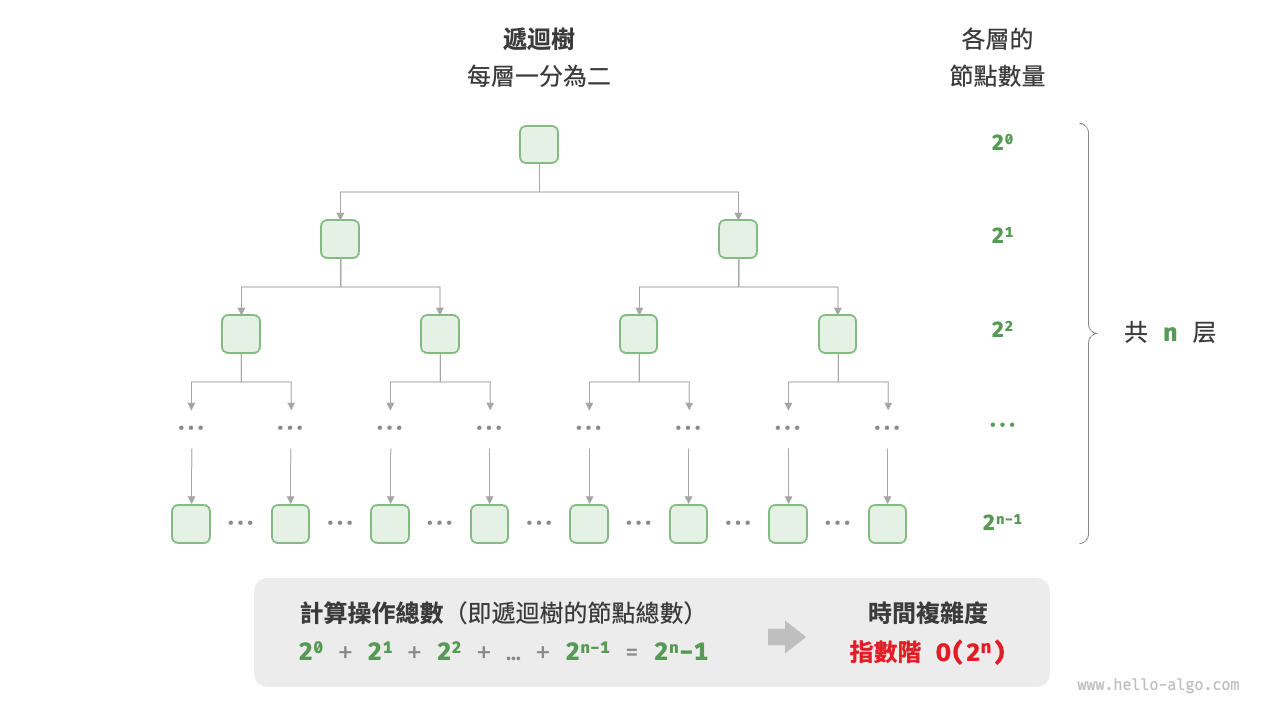
圖 2-11 指數階的時間複雜度
在實際演算法中,指數階常出現於遞迴函式中。例如在以下程式碼中,其遞迴地一分為二,經過 \(n\) 次分裂後停止:
視覺化執行
指數階增長非常迅速,在窮舉法(暴力搜尋、回溯等)中比較常見。對於資料規模較大的問題,指數階是不可接受的,通常需要使用動態規劃或貪婪演算法等來解決。
5. 對數階 \(O(\log n)\)¶
與指數階相反,對數階反映了“每輪縮減到一半”的情況。設輸入資料大小為 \(n\) ,由於每輪縮減到一半,因此迴圈次數是 \(\log_2 n\) ,即 \(2^n\) 的反函式。
圖 2-12 和以下程式碼模擬了“每輪縮減到一半”的過程,時間複雜度為 \(O(\log_2 n)\) ,簡記為 \(O(\log n)\) :
視覺化執行
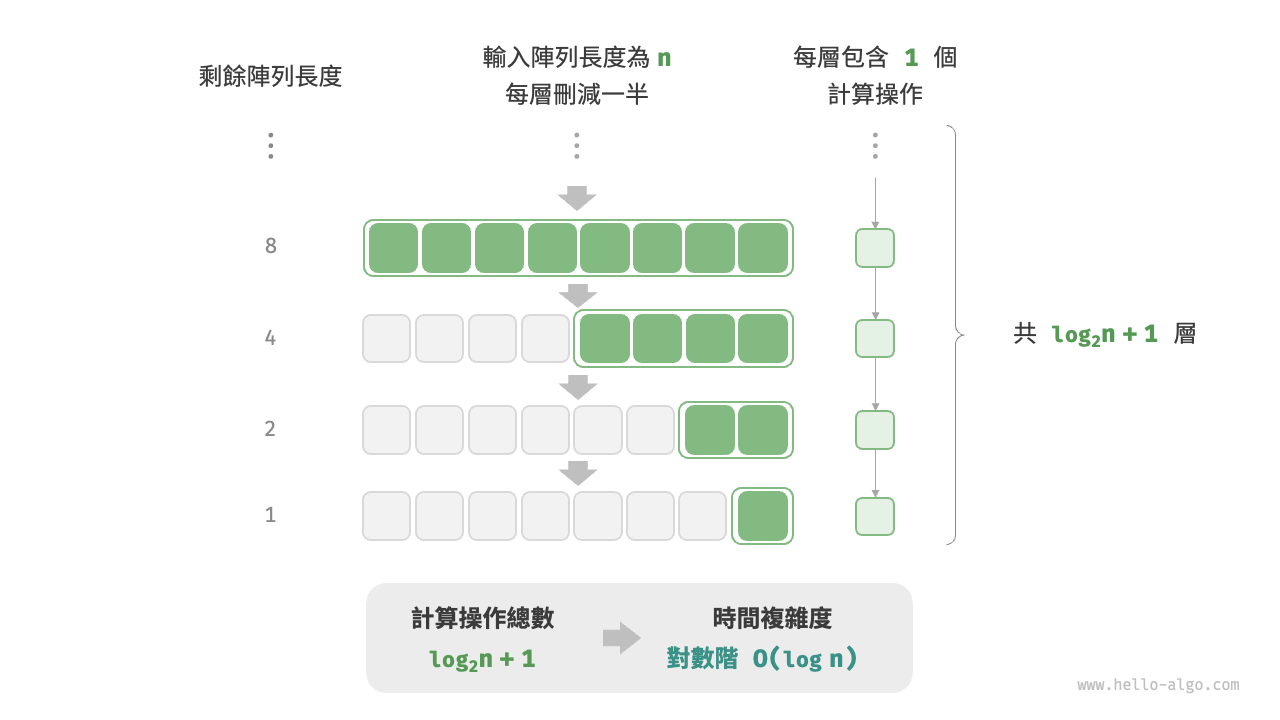
圖 2-12 對數階的時間複雜度
與指數階類似,對數階也常出現於遞迴函式中。以下程式碼形成了一棵高度為 \(\log_2 n\) 的遞迴樹:
視覺化執行
對數階常出現於基於分治策略的演算法中,體現了“一分為多”和“化繁為簡”的演算法思想。它增長緩慢,是僅次於常數階的理想的時間複雜度。
\(O(\log n)\) 的底數是多少?
準確來說,“一分為 \(m\)”對應的時間複雜度是 \(O(\log_m n)\) 。而透過對數換底公式,我們可以得到具有不同底數、相等的時間複雜度:
也就是說,底數 \(m\) 可以在不影響複雜度的前提下轉換。因此我們通常會省略底數 \(m\) ,將對數階直接記為 \(O(\log n)\) 。
6. 線性對數階 \(O(n \log n)\)¶
線性對數階常出現於巢狀迴圈中,兩層迴圈的時間複雜度分別為 \(O(\log n)\) 和 \(O(n)\) 。相關程式碼如下:
視覺化執行
圖 2-13 展示了線性對數階的生成方式。二元樹的每一層的操作總數都為 \(n\) ,樹共有 \(\log_2 n + 1\) 層,因此時間複雜度為 \(O(n \log n)\) 。

圖 2-13 線性對數階的時間複雜度
主流排序演算法的時間複雜度通常為 \(O(n \log n)\) ,例如快速排序、合併排序、堆積排序等。
7. 階乘階 \(O(n!)\)¶
階乘階對應數學上的“全排列”問題。給定 \(n\) 個互不重複的元素,求其所有可能的排列方案,方案數量為:
階乘通常使用遞迴實現。如圖 2-14 和以下程式碼所示,第一層分裂出 \(n\) 個,第二層分裂出 \(n - 1\) 個,以此類推,直至第 \(n\) 層時停止分裂:
視覺化執行

圖 2-14 階乘階的時間複雜度
請注意,因為當 \(n \geq 4\) 時恆有 \(n! > 2^n\) ,所以階乘階比指數階增長得更快,在 \(n\) 較大時也是不可接受的。
2.3.5 最差、最佳、平均時間複雜度¶
演算法的時間效率往往不是固定的,而是與輸入資料的分佈有關。假設輸入一個長度為 \(n\) 的陣列 nums ,其中 nums 由從 \(1\) 至 \(n\) 的數字組成,每個數字只出現一次;但元素順序是隨機打亂的,任務目標是返回元素 \(1\) 的索引。我們可以得出以下結論。
- 當
nums = [?, ?, ..., 1],即當末尾元素是 \(1\) 時,需要完整走訪陣列,達到最差時間複雜度 \(O(n)\) 。 - 當
nums = [1, ?, ?, ...],即當首個元素為 \(1\) 時,無論陣列多長都不需要繼續走訪,達到最佳時間複雜度 \(\Omega(1)\) 。
“最差時間複雜度”對應函式漸近上界,使用大 \(O\) 記號表示。相應地,“最佳時間複雜度”對應函式漸近下界,用 \(\Omega\) 記號表示:
def random_numbers(n: int) -> list[int]:
"""生成一個陣列,元素為: 1, 2, ..., n ,順序被打亂"""
# 生成陣列 nums =: 1, 2, 3, ..., n
nums = [i for i in range(1, n + 1)]
# 隨機打亂陣列元素
random.shuffle(nums)
return nums
def find_one(nums: list[int]) -> int:
"""查詢陣列 nums 中數字 1 所在索引"""
for i in range(len(nums)):
# 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
# 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if nums[i] == 1:
return i
return -1
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
vector<int> randomNumbers(int n) {
vector<int> nums(n);
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 使用系統時間生成隨機種子
unsigned seed = chrono::system_clock::now().time_since_epoch().count();
// 隨機打亂陣列元素
shuffle(nums.begin(), nums.end(), default_random_engine(seed));
return nums;
}
/* 查詢陣列 nums 中數字 1 所在索引 */
int findOne(vector<int> &nums) {
for (int i = 0; i < nums.size(); i++) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
int[] randomNumbers(int n) {
Integer[] nums = new Integer[n];
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 隨機打亂陣列元素
Collections.shuffle(Arrays.asList(nums));
// Integer[] -> int[]
int[] res = new int[n];
for (int i = 0; i < n; i++) {
res[i] = nums[i];
}
return res;
}
/* 查詢陣列 nums 中數字 1 所在索引 */
int findOne(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
int[] RandomNumbers(int n) {
int[] nums = new int[n];
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 隨機打亂陣列元素
for (int i = 0; i < nums.Length; i++) {
int index = new Random().Next(i, nums.Length);
(nums[i], nums[index]) = (nums[index], nums[i]);
}
return nums;
}
/* 查詢陣列 nums 中數字 1 所在索引 */
int FindOne(int[] nums) {
for (int i = 0; i < nums.Length; i++) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
func randomNumbers(n int) []int {
nums := make([]int, n)
// 生成陣列 nums = { 1, 2, 3, ..., n }
for i := 0; i < n; i++ {
nums[i] = i + 1
}
// 隨機打亂陣列元素
rand.Shuffle(len(nums), func(i, j int) {
nums[i], nums[j] = nums[j], nums[i]
})
return nums
}
/* 查詢陣列 nums 中數字 1 所在索引 */
func findOne(nums []int) int {
for i := 0; i < len(nums); i++ {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if nums[i] == 1 {
return i
}
}
return -1
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
func randomNumbers(n: Int) -> [Int] {
// 生成陣列 nums = { 1, 2, 3, ..., n }
var nums = Array(1 ... n)
// 隨機打亂陣列元素
nums.shuffle()
return nums
}
/* 查詢陣列 nums 中數字 1 所在索引 */
func findOne(nums: [Int]) -> Int {
for i in nums.indices {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if nums[i] == 1 {
return i
}
}
return -1
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
function randomNumbers(n) {
const nums = Array(n);
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 隨機打亂陣列元素
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* 查詢陣列 nums 中數字 1 所在索引 */
function findOne(nums) {
for (let i = 0; i < nums.length; i++) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
function randomNumbers(n: number): number[] {
const nums = Array(n);
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 隨機打亂陣列元素
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* 查詢陣列 nums 中數字 1 所在索引 */
function findOne(nums: number[]): number {
for (let i = 0; i < nums.length; i++) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
List<int> randomNumbers(int n) {
final nums = List.filled(n, 0);
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (var i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 隨機打亂陣列元素
nums.shuffle();
return nums;
}
/* 查詢陣列 nums 中數字 1 所在索引 */
int findOne(List<int> nums) {
for (var i = 0; i < nums.length; i++) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] == 1) return i;
}
return -1;
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
fn random_numbers(n: i32) -> Vec<i32> {
// 生成陣列 nums = { 1, 2, 3, ..., n }
let mut nums = (1..=n).collect::<Vec<i32>>();
// 隨機打亂陣列元素
nums.shuffle(&mut thread_rng());
nums
}
/* 查詢陣列 nums 中數字 1 所在索引 */
fn find_one(nums: &[i32]) -> Option<usize> {
for i in 0..nums.len() {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if nums[i] == 1 {
return Some(i);
}
}
None
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
int *randomNumbers(int n) {
// 分配堆積區記憶體(建立一維可變長陣列:陣列中元素數量為 n ,元素型別為 int )
int *nums = (int *)malloc(n * sizeof(int));
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 隨機打亂陣列元素
for (int i = n - 1; i > 0; i--) {
int j = rand() % (i + 1);
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
return nums;
}
/* 查詢陣列 nums 中數字 1 所在索引 */
int findOne(int *nums, int n) {
for (int i = 0; i < n; i++) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂 */
fun randomNumbers(n: Int): Array<Int?> {
val nums = IntArray(n)
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (i in 0..<n) {
nums[i] = i + 1
}
// 隨機打亂陣列元素
nums.shuffle()
val res = arrayOfNulls<Int>(n)
for (i in 0..<n) {
res[i] = nums[i]
}
return res
}
/* 查詢陣列 nums 中數字 1 所在索引 */
fun findOne(nums: Array<Int?>): Int {
for (i in nums.indices) {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (nums[i] == 1)
return i
}
return -1
}
### 生成一個陣列,元素為: 1, 2, ..., n ,順序被打亂 ###
def random_numbers(n)
# 生成陣列 nums =: 1, 2, 3, ..., n
nums = Array.new(n) { |i| i + 1 }
# 隨機打亂陣列元素
nums.shuffle!
end
### 查詢陣列 nums 中數字 1 所在索引 ###
def find_one(nums)
for i in 0...nums.length
# 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
# 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
return i if nums[i] == 1
end
-1
end
// 生成一個陣列,元素為 { 1, 2, ..., n },順序被打亂
fn randomNumbers(comptime n: usize) [n]i32 {
var nums: [n]i32 = undefined;
// 生成陣列 nums = { 1, 2, 3, ..., n }
for (&nums, 0..) |*num, i| {
num.* = @as(i32, @intCast(i)) + 1;
}
// 隨機打亂陣列元素
const rand = std.crypto.random;
rand.shuffle(i32, &nums);
return nums;
}
// 查詢陣列 nums 中數字 1 所在索引
fn findOne(nums: []i32) i32 {
for (nums, 0..) |num, i| {
// 當元素 1 在陣列頭部時,達到最佳時間複雜度 O(1)
// 當元素 1 在陣列尾部時,達到最差時間複雜度 O(n)
if (num == 1) return @intCast(i);
}
return -1;
}
視覺化執行
值得說明的是,我們在實際中很少使用最佳時間複雜度,因為通常只有在很小機率下才能達到,可能會帶來一定的誤導性。而最差時間複雜度更為實用,因為它給出了一個效率安全值,讓我們可以放心地使用演算法。
從上述示例可以看出,最差時間複雜度和最佳時間複雜度只出現於“特殊的資料分佈”,這些情況的出現機率可能很小,並不能真實地反映演算法執行效率。相比之下,平均時間複雜度可以體現演算法在隨機輸入資料下的執行效率,用 \(\Theta\) 記號來表示。
對於部分演算法,我們可以簡單地推算出隨機資料分佈下的平均情況。比如上述示例,由於輸入陣列是被打亂的,因此元素 \(1\) 出現在任意索引的機率都是相等的,那麼演算法的平均迴圈次數就是陣列長度的一半 \(n / 2\) ,平均時間複雜度為 \(\Theta(n / 2) = \Theta(n)\) 。
但對於較為複雜的演算法,計算平均時間複雜度往往比較困難,因為很難分析出在資料分佈下的整體數學期望。在這種情況下,我們通常使用最差時間複雜度作為演算法效率的評判標準。
為什麼很少看到 \(\Theta\) 符號?
可能由於 \(O\) 符號過於朗朗上口,因此我們常常使用它來表示平均時間複雜度。但從嚴格意義上講,這種做法並不規範。在本書和其他資料中,若遇到類似“平均時間複雜度 \(O(n)\)”的表述,請將其直接理解為 \(\Theta(n)\) 。