2.3 Time Complexity¶
Time complexity is a concept used to measure how the run time of an algorithm increases with the size of the input data. Understanding time complexity is crucial for accurately assessing the efficiency of an algorithm.
- Determining the Running Platform: This includes hardware configuration, programming language, system environment, etc., all of which can affect the efficiency of code execution.
- Evaluating the Run Time for Various Computational Operations: For instance, an addition operation
+might take 1 ns, a multiplication operation*might take 10 ns, a print operationprint()might take 5 ns, etc. - Counting All the Computational Operations in the Code: Summing the execution times of all these operations gives the total run time.
For example, consider the following code with an input size of \(n\):
Using the above method, the run time of the algorithm can be calculated as \((6n + 12)\) ns:
However, in practice, counting the run time of an algorithm is neither practical nor reasonable. First, we don't want to tie the estimated time to the running platform, as algorithms need to run on various platforms. Second, it's challenging to know the run time for each type of operation, making the estimation process difficult.
2.3.1 Assessing Time Growth Trend¶
Time complexity analysis does not count the algorithm's run time, but rather the growth trend of the run time as the data volume increases.
Let's understand this concept of "time growth trend" with an example. Assume the input data size is \(n\), and consider three algorithms A, B, and C:
// Time complexity of algorithm A: constant order
void algorithm_A(int n) {
cout << 0 << endl;
}
// Time complexity of algorithm B: linear order
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
cout << 0 << endl;
}
}
// Time complexity of algorithm C: constant order
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
cout << 0 << endl;
}
}
// Time complexity of algorithm A: constant order
void algorithm_A(int n) {
System.out.println(0);
}
// Time complexity of algorithm B: linear order
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
System.out.println(0);
}
}
// Time complexity of algorithm C: constant order
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
System.out.println(0);
}
}
// Time complexity of algorithm A: constant order
void AlgorithmA(int n) {
Console.WriteLine(0);
}
// Time complexity of algorithm B: linear order
void AlgorithmB(int n) {
for (int i = 0; i < n; i++) {
Console.WriteLine(0);
}
}
// Time complexity of algorithm C: constant order
void AlgorithmC(int n) {
for (int i = 0; i < 1000000; i++) {
Console.WriteLine(0);
}
}
// Time complexity of algorithm A: constant order
func algorithm_A(n int) {
fmt.Println(0)
}
// Time complexity of algorithm B: linear order
func algorithm_B(n int) {
for i := 0; i < n; i++ {
fmt.Println(0)
}
}
// Time complexity of algorithm C: constant order
func algorithm_C(n int) {
for i := 0; i < 1000000; i++ {
fmt.Println(0)
}
}
// Time complexity of algorithm A: constant order
func algorithmA(n: Int) {
print(0)
}
// Time complexity of algorithm B: linear order
func algorithmB(n: Int) {
for _ in 0 ..< n {
print(0)
}
}
// Time complexity of algorithm C: constant order
func algorithmC(n: Int) {
for _ in 0 ..< 1000000 {
print(0)
}
}
// Time complexity of algorithm A: constant order
function algorithm_A(n) {
console.log(0);
}
// Time complexity of algorithm B: linear order
function algorithm_B(n) {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// Time complexity of algorithm C: constant order
function algorithm_C(n) {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
// Time complexity of algorithm A: constant order
function algorithm_A(n: number): void {
console.log(0);
}
// Time complexity of algorithm B: linear order
function algorithm_B(n: number): void {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// Time complexity of algorithm C: constant order
function algorithm_C(n: number): void {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}
// Time complexity of algorithm A: constant order
void algorithmA(int n) {
print(0);
}
// Time complexity of algorithm B: linear order
void algorithmB(int n) {
for (int i = 0; i < n; i++) {
print(0);
}
}
// Time complexity of algorithm C: constant order
void algorithmC(int n) {
for (int i = 0; i < 1000000; i++) {
print(0);
}
}
// Time complexity of algorithm A: constant order
fn algorithm_A(n: i32) {
println!("{}", 0);
}
// Time complexity of algorithm B: linear order
fn algorithm_B(n: i32) {
for _ in 0..n {
println!("{}", 0);
}
}
// Time complexity of algorithm C: constant order
fn algorithm_C(n: i32) {
for _ in 0..1000000 {
println!("{}", 0);
}
}
// Time complexity of algorithm A: constant order
void algorithm_A(int n) {
printf("%d", 0);
}
// Time complexity of algorithm B: linear order
void algorithm_B(int n) {
for (int i = 0; i < n; i++) {
printf("%d", 0);
}
}
// Time complexity of algorithm C: constant order
void algorithm_C(int n) {
for (int i = 0; i < 1000000; i++) {
printf("%d", 0);
}
}
// Time complexity of algorithm A: constant order
fn algorithm_A(n: usize) void {
_ = n;
std.debug.print("{}\n", .{0});
}
// Time complexity of algorithm B: linear order
fn algorithm_B(n: i32) void {
for (0..n) |_| {
std.debug.print("{}\n", .{0});
}
}
// Time complexity of algorithm C: constant order
fn algorithm_C(n: i32) void {
_ = n;
for (0..1000000) |_| {
std.debug.print("{}\n", .{0});
}
}
The following figure shows the time complexities of these three algorithms.
- Algorithm
Ahas just one print operation, and its run time does not grow with \(n\). Its time complexity is considered "constant order." - Algorithm
Binvolves a print operation looping \(n\) times, and its run time grows linearly with \(n\). Its time complexity is "linear order." - Algorithm
Chas a print operation looping 1,000,000 times. Although it takes a long time, it is independent of the input data size \(n\). Therefore, the time complexity ofCis the same asA, which is "constant order."

Figure 2-7 Time Growth Trend of Algorithms A, B, and C
Compared to directly counting the run time of an algorithm, what are the characteristics of time complexity analysis?
- Time complexity effectively assesses algorithm efficiency. For instance, algorithm
Bhas linearly growing run time, which is slower than algorithmAwhen \(n > 1\) and slower thanCwhen \(n > 1,000,000\). In fact, as long as the input data size \(n\) is sufficiently large, a "constant order" complexity algorithm will always be better than a "linear order" one, demonstrating the essence of time growth trend. - Time complexity analysis is more straightforward. Obviously, the running platform and the types of computational operations are irrelevant to the trend of run time growth. Therefore, in time complexity analysis, we can simply treat the execution time of all computational operations as the same "unit time," simplifying the "computational operation run time count" to a "computational operation count." This significantly reduces the complexity of estimation.
- Time complexity has its limitations. For example, although algorithms
AandChave the same time complexity, their actual run times can be quite different. Similarly, even though algorithmBhas a higher time complexity thanC, it is clearly superior when the input data size \(n\) is small. In these cases, it's difficult to judge the efficiency of algorithms based solely on time complexity. Nonetheless, despite these issues, complexity analysis remains the most effective and commonly used method for evaluating algorithm efficiency.
2.3.2 Asymptotic Upper Bound¶
Consider a function with an input size of \(n\):
Given a function that represents the number of operations of an algorithm as a function of the input size \(n\), denoted as \(T(n)\), consider the following example:
Since \(T(n)\) is a linear function, its growth trend is linear, and therefore, its time complexity is of linear order, denoted as \(O(n)\). This mathematical notation, known as "big-O notation," represents the "asymptotic upper bound" of the function \(T(n)\).
In essence, time complexity analysis is about finding the asymptotic upper bound of the "number of operations \(T(n)\)". It has a precise mathematical definition.
Asymptotic Upper Bound
If there exist positive real numbers \(c\) and \(n_0\) such that for all \(n > n_0\), \(T(n) \leq c \cdot f(n)\), then \(f(n)\) is considered an asymptotic upper bound of \(T(n)\), denoted as \(T(n) = O(f(n))\).
As illustrated below, calculating the asymptotic upper bound involves finding a function \(f(n)\) such that, as \(n\) approaches infinity, \(T(n)\) and \(f(n)\) have the same growth order, differing only by a constant factor \(c\).

Figure 2-8 Asymptotic Upper Bound of a Function
2.3.3 Calculation Method¶
While the concept of asymptotic upper bound might seem mathematically dense, you don't need to fully grasp it right away. Let's first understand the method of calculation, which can be practiced and comprehended over time.
Once \(f(n)\) is determined, we obtain the time complexity \(O(f(n))\). But how do we determine the asymptotic upper bound \(f(n)\)? This process generally involves two steps: counting the number of operations and determining the asymptotic upper bound.
1. Step 1: Counting the Number of Operations¶
This step involves going through the code line by line. However, due to the presence of the constant \(c\) in \(c \cdot f(n)\), all coefficients and constant terms in \(T(n)\) can be ignored. This principle allows for simplification techniques in counting operations.
- Ignore constant terms in \(T(n)\), as they do not affect the time complexity being independent of \(n\).
- Omit all coefficients. For example, looping \(2n\), \(5n + 1\) times, etc., can be simplified to \(n\) times since the coefficient before \(n\) does not impact the time complexity.
- Use multiplication for nested loops. The total number of operations equals the product of the number of operations in each loop, applying the simplification techniques from points 1 and 2 for each loop level.
Given a function, we can use these techniques to count operations:
The formula below shows the counting results before and after simplification, both leading to a time complexity of \(O(n^2)\):
2. Step 2: Determining the Asymptotic Upper Bound¶
The time complexity is determined by the highest order term in \(T(n)\). This is because, as \(n\) approaches infinity, the highest order term dominates, rendering the influence of other terms negligible.
The following table illustrates examples of different operation counts and their corresponding time complexities. Some exaggerated values are used to emphasize that coefficients cannot alter the order of growth. When \(n\) becomes very large, these constants become insignificant.
Table: Time Complexity for Different Operation Counts
| Operation Count \(T(n)\) | Time Complexity \(O(f(n))\) |
|---|---|
| \(100000\) | \(O(1)\) |
| \(3n + 2\) | \(O(n)\) |
| \(2n^2 + 3n + 2\) | \(O(n^2)\) |
| \(n^3 + 10000n^2\) | \(O(n^3)\) |
| \(2^n + 10000n^{10000}\) | \(O(2^n)\) |
2.3.4 Common Types of Time Complexity¶
Let's consider the input data size as \(n\). The common types of time complexities are illustrated below, arranged from lowest to highest:

Figure 2-9 Common Types of Time Complexity
1. Constant Order \(O(1)\)¶
Constant order means the number of operations is independent of the input data size \(n\). In the following function, although the number of operations size might be large, the time complexity remains \(O(1)\) as it's unrelated to \(n\):
Visualizing Code
2. Linear Order \(O(n)\)¶
Linear order indicates the number of operations grows linearly with the input data size \(n\). Linear order commonly appears in single-loop structures:
Visualizing Code
Operations like array traversal and linked list traversal have a time complexity of \(O(n)\), where \(n\) is the length of the array or list:
Visualizing Code
It's important to note that the input data size \(n\) should be determined based on the type of input data. For example, in the first example, \(n\) represents the input data size, while in the second example, the length of the array \(n\) is the data size.
3. Quadratic Order \(O(n^2)\)¶
Quadratic order means the number of operations grows quadratically with the input data size \(n\). Quadratic order typically appears in nested loops, where both the outer and inner loops have a time complexity of \(O(n)\), resulting in an overall complexity of \(O(n^2)\):
Visualizing Code
The following image compares constant order, linear order, and quadratic order time complexities.

Figure 2-10 Constant, Linear, and Quadratic Order Time Complexities
For instance, in bubble sort, the outer loop runs \(n - 1\) times, and the inner loop runs \(n-1\), \(n-2\), ..., \(2\), \(1\) times, averaging \(n / 2\) times, resulting in a time complexity of \(O((n - 1) n / 2) = O(n^2)\):
def bubble_sort(nums: list[int]) -> int:
"""平方阶(冒泡排序)"""
count = 0 # 计数器
# 外循环:未排序区间为 [0, i]
for i in range(len(nums) - 1, 0, -1):
# 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for j in range(i):
if nums[j] > nums[j + 1]:
# 交换 nums[j] 与 nums[j + 1]
tmp: int = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 元素交换包含 3 个单元操作
return count
/* 平方阶(冒泡排序) */
int bubbleSort(vector<int> &nums) {
int count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for (int i = nums.size() - 1; i > 0; i--) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
/* 平方阶(冒泡排序) */
int bubbleSort(int[] nums) {
int count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for (int i = nums.length - 1; i > 0; i--) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
/* 平方阶(冒泡排序) */
int BubbleSort(int[] nums) {
int count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for (int i = nums.Length - 1; i > 0; i--) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
(nums[j + 1], nums[j]) = (nums[j], nums[j + 1]);
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
/* 平方阶(冒泡排序) */
func bubbleSort(nums []int) int {
count := 0 // 计数器
// 外循环:未排序区间为 [0, i]
for i := len(nums) - 1; i > 0; i-- {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for j := 0; j < i; j++ {
if nums[j] > nums[j+1] {
// 交换 nums[j] 与 nums[j + 1]
tmp := nums[j]
nums[j] = nums[j+1]
nums[j+1] = tmp
count += 3 // 元素交换包含 3 个单元操作
}
}
}
return count
}
/* 平方阶(冒泡排序) */
func bubbleSort(nums: inout [Int]) -> Int {
var count = 0 // 计数器
// 外循环:未排序区间为 [0, i]
for i in stride(from: nums.count - 1, to: 0, by: -1) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for j in 0 ..< i {
if nums[j] > nums[j + 1] {
// 交换 nums[j] 与 nums[j + 1]
let tmp = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 // 元素交换包含 3 个单元操作
}
}
}
return count
}
/* 平方阶(冒泡排序) */
function bubbleSort(nums) {
let count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
/* 平方阶(冒泡排序) */
function bubbleSort(nums: number[]): number {
let count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for (let i = nums.length - 1; i > 0; i--) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
/* 平方阶(冒泡排序) */
int bubbleSort(List<int> nums) {
int count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for (var i = nums.length - 1; i > 0; i--) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for (var j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
/* 平方阶(冒泡排序) */
fn bubble_sort(nums: &mut [i32]) -> i32 {
let mut count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for i in (1..nums.len()).rev() {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for j in 0..i {
if nums[j] > nums[j + 1] {
// 交换 nums[j] 与 nums[j + 1]
let tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
count
}
/* 平方阶(冒泡排序) */
int bubbleSort(int *nums, int n) {
int count = 0; // 计数器
// 外循环:未排序区间为 [0, i]
for (int i = n - 1; i > 0; i--) {
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
// 平方阶(冒泡排序)
fn bubbleSort(nums: []i32) i32 {
var count: i32 = 0; // 计数器
// 外循环:未排序区间为 [0, i]
var i: i32 = @as(i32, @intCast(nums.len)) - 1;
while (i > 0) : (i -= 1) {
var j: usize = 0;
// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
while (j < i) : (j += 1) {
if (nums[j] > nums[j + 1]) {
// 交换 nums[j] 与 nums[j + 1]
var tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
count += 3; // 元素交换包含 3 个单元操作
}
}
}
return count;
}
Visualizing Code
4. Exponential Order \(O(2^n)\)¶
Biological "cell division" is a classic example of exponential order growth: starting with one cell, it becomes two after one division, four after two divisions, and so on, resulting in \(2^n\) cells after \(n\) divisions.
The following image and code simulate the cell division process, with a time complexity of \(O(2^n)\):
// 指数阶(循环实现)
fn exponential(n: i32) i32 {
var count: i32 = 0;
var bas: i32 = 1;
var i: i32 = 0;
// 细胞每轮一分为二,形成数列 1, 2, 4, 8, ..., 2^(n-1)
while (i < n) : (i += 1) {
var j: i32 = 0;
while (j < bas) : (j += 1) {
count += 1;
}
bas *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
Visualizing Code

Figure 2-11 Exponential Order Time Complexity
In practice, exponential order often appears in recursive functions. For example, in the code below, it recursively splits into two halves, stopping after \(n\) divisions:
Visualizing Code
Exponential order growth is extremely rapid and is commonly seen in exhaustive search methods (brute force, backtracking, etc.). For large-scale problems, exponential order is unacceptable, often requiring dynamic programming or greedy algorithms as solutions.
5. Logarithmic Order \(O(\log n)\)¶
In contrast to exponential order, logarithmic order reflects situations where "the size is halved each round." Given an input data size \(n\), since the size is halved each round, the number of iterations is \(\log_2 n\), the inverse function of \(2^n\).
The following image and code simulate the "halving each round" process, with a time complexity of \(O(\log_2 n)\), commonly abbreviated as \(O(\log n)\):
Visualizing Code
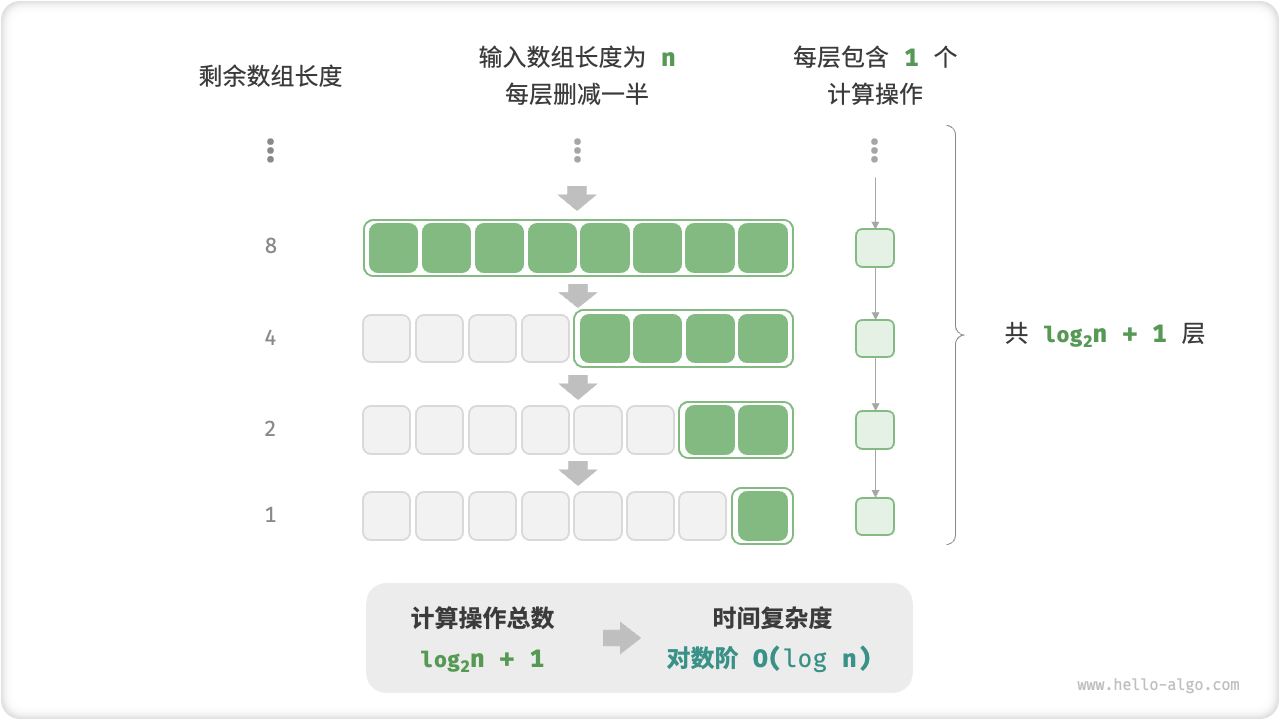
Figure 2-12 Logarithmic Order Time Complexity
Like exponential order, logarithmic order also frequently appears in recursive functions. The code below forms a recursive tree of height \(\log_2 n\):
Visualizing Code
Logarithmic order is typical in algorithms based on the divide-and-conquer strategy, embodying the "split into many" and "simplify complex problems" approach. It's slow-growing and is the most ideal time complexity after constant order.
What is the base of \(O(\log n)\)?
Technically, "splitting into \(m\)" corresponds to a time complexity of \(O(\log_m n)\). Using the logarithm base change formula, we can equate different logarithmic complexities:
This means the base \(m\) can be changed without affecting the complexity. Therefore, we often omit the base \(m\) and simply denote logarithmic order as \(O(\log n)\).
6. Linear-Logarithmic Order \(O(n \log n)\)¶
Linear-logarithmic order often appears in nested loops, with the complexities of the two loops being \(O(\log n)\) and \(O(n)\) respectively. The related code is as follows:
Visualizing Code
The image below demonstrates how linear-logarithmic order is generated. Each level of a binary tree has \(n\) operations, and the tree has \(\log_2 n + 1\) levels, resulting in a time complexity of \(O(n \log n)\).

Figure 2-13 Linear-Logarithmic Order Time Complexity
Mainstream sorting algorithms typically have a time complexity of \(O(n \log n)\), such as quicksort, mergesort, and heapsort.
7. Factorial Order \(O(n!)\)¶
Factorial order corresponds to the mathematical problem of "full permutation." Given \(n\) distinct elements, the total number of possible permutations is:
Factorials are typically implemented using recursion. As shown in the image and code below, the first level splits into \(n\) branches, the second level into \(n - 1\) branches, and so on, stopping after the \(n\)th level:
Visualizing Code

Figure 2-14 Factorial Order Time Complexity
Note that factorial order grows even faster than exponential order; it's unacceptable for larger \(n\) values.
2.3.5 Worst, Best, and Average Time Complexities¶
The time efficiency of an algorithm is often not fixed but depends on the distribution of the input data. Assume we have an array nums of length \(n\), consisting of numbers from \(1\) to \(n\), each appearing only once, but in a randomly shuffled order. The task is to return the index of the element \(1\). We can draw the following conclusions:
- When
nums = [?, ?, ..., 1], that is, when the last element is \(1\), it requires a complete traversal of the array, achieving the worst-case time complexity of \(O(n)\). - When
nums = [1, ?, ?, ...], that is, when the first element is \(1\), no matter the length of the array, no further traversal is needed, achieving the best-case time complexity of \(\Omega(1)\).
The "worst-case time complexity" corresponds to the asymptotic upper bound, denoted by the big \(O\) notation. Correspondingly, the "best-case time complexity" corresponds to the asymptotic lower bound, denoted by \(\Omega\):
def random_numbers(n: int) -> list[int]:
"""生成一个数组,元素为: 1, 2, ..., n ,顺序被打乱"""
# 生成数组 nums =: 1, 2, 3, ..., n
nums = [i for i in range(1, n + 1)]
# 随机打乱数组元素
random.shuffle(nums)
return nums
def find_one(nums: list[int]) -> int:
"""查找数组 nums 中数字 1 所在索引"""
for i in range(len(nums)):
# 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
# 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if nums[i] == 1:
return i
return -1
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
vector<int> randomNumbers(int n) {
vector<int> nums(n);
// 生成数组 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 使用系统时间生成随机种子
unsigned seed = chrono::system_clock::now().time_since_epoch().count();
// 随机打乱数组元素
shuffle(nums.begin(), nums.end(), default_random_engine(seed));
return nums;
}
/* 查找数组 nums 中数字 1 所在索引 */
int findOne(vector<int> &nums) {
for (int i = 0; i < nums.size(); i++) {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
int[] randomNumbers(int n) {
Integer[] nums = new Integer[n];
// 生成数组 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 随机打乱数组元素
Collections.shuffle(Arrays.asList(nums));
// Integer[] -> int[]
int[] res = new int[n];
for (int i = 0; i < n; i++) {
res[i] = nums[i];
}
return res;
}
/* 查找数组 nums 中数字 1 所在索引 */
int findOne(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
int[] RandomNumbers(int n) {
int[] nums = new int[n];
// 生成数组 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 随机打乱数组元素
for (int i = 0; i < nums.Length; i++) {
int index = new Random().Next(i, nums.Length);
(nums[i], nums[index]) = (nums[index], nums[i]);
}
return nums;
}
/* 查找数组 nums 中数字 1 所在索引 */
int FindOne(int[] nums) {
for (int i = 0; i < nums.Length; i++) {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
func randomNumbers(n int) []int {
nums := make([]int, n)
// 生成数组 nums = { 1, 2, 3, ..., n }
for i := 0; i < n; i++ {
nums[i] = i + 1
}
// 随机打乱数组元素
rand.Shuffle(len(nums), func(i, j int) {
nums[i], nums[j] = nums[j], nums[i]
})
return nums
}
/* 查找数组 nums 中数字 1 所在索引 */
func findOne(nums []int) int {
for i := 0; i < len(nums); i++ {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if nums[i] == 1 {
return i
}
}
return -1
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
func randomNumbers(n: Int) -> [Int] {
// 生成数组 nums = { 1, 2, 3, ..., n }
var nums = Array(1 ... n)
// 随机打乱数组元素
nums.shuffle()
return nums
}
/* 查找数组 nums 中数字 1 所在索引 */
func findOne(nums: [Int]) -> Int {
for i in nums.indices {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if nums[i] == 1 {
return i
}
}
return -1
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
function randomNumbers(n) {
const nums = Array(n);
// 生成数组 nums = { 1, 2, 3, ..., n }
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 随机打乱数组元素
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* 查找数组 nums 中数字 1 所在索引 */
function findOne(nums) {
for (let i = 0; i < nums.length; i++) {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
function randomNumbers(n: number): number[] {
const nums = Array(n);
// 生成数组 nums = { 1, 2, 3, ..., n }
for (let i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 随机打乱数组元素
for (let i = 0; i < n; i++) {
const r = Math.floor(Math.random() * (i + 1));
const temp = nums[i];
nums[i] = nums[r];
nums[r] = temp;
}
return nums;
}
/* 查找数组 nums 中数字 1 所在索引 */
function findOne(nums: number[]): number {
for (let i = 0; i < nums.length; i++) {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (nums[i] === 1) {
return i;
}
}
return -1;
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
List<int> randomNumbers(int n) {
final nums = List.filled(n, 0);
// 生成数组 nums = { 1, 2, 3, ..., n }
for (var i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 随机打乱数组元素
nums.shuffle();
return nums;
}
/* 查找数组 nums 中数字 1 所在索引 */
int findOne(List<int> nums) {
for (var i = 0; i < nums.length; i++) {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (nums[i] == 1) return i;
}
return -1;
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
fn random_numbers(n: i32) -> Vec<i32> {
// 生成数组 nums = { 1, 2, 3, ..., n }
let mut nums = (1..=n).collect::<Vec<i32>>();
// 随机打乱数组元素
nums.shuffle(&mut thread_rng());
nums
}
/* 查找数组 nums 中数字 1 所在索引 */
fn find_one(nums: &[i32]) -> Option<usize> {
for i in 0..nums.len() {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if nums[i] == 1 {
return Some(i);
}
}
None
}
/* 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱 */
int *randomNumbers(int n) {
// 分配堆区内存(创建一维可变长数组:数组中元素数量为 n ,元素类型为 int )
int *nums = (int *)malloc(n * sizeof(int));
// 生成数组 nums = { 1, 2, 3, ..., n }
for (int i = 0; i < n; i++) {
nums[i] = i + 1;
}
// 随机打乱数组元素
for (int i = n - 1; i > 0; i--) {
int j = rand() % (i + 1);
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
return nums;
}
/* 查找数组 nums 中数字 1 所在索引 */
int findOne(int *nums, int n) {
for (int i = 0; i < n; i++) {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (nums[i] == 1)
return i;
}
return -1;
}
// 生成一个数组,元素为 { 1, 2, ..., n },顺序被打乱
fn randomNumbers(comptime n: usize) [n]i32 {
var nums: [n]i32 = undefined;
// 生成数组 nums = { 1, 2, 3, ..., n }
for (&nums, 0..) |*num, i| {
num.* = @as(i32, @intCast(i)) + 1;
}
// 随机打乱数组元素
const rand = std.crypto.random;
rand.shuffle(i32, &nums);
return nums;
}
// 查找数组 nums 中数字 1 所在索引
fn findOne(nums: []i32) i32 {
for (nums, 0..) |num, i| {
// 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
// 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if (num == 1) return @intCast(i);
}
return -1;
}
Visualizing Code
It's important to note that the best-case time complexity is rarely used in practice, as it is usually only achievable under very low probabilities and might be misleading. The worst-case time complexity is more practical as it provides a safety value for efficiency, allowing us to confidently use the algorithm.
From the above example, it's clear that both the worst-case and best-case time complexities only occur under "special data distributions," which may have a small probability of occurrence and may not accurately reflect the algorithm's run efficiency. In contrast, the average time complexity can reflect the algorithm's efficiency under random input data, denoted by the \(\Theta\) notation.
For some algorithms, we can simply estimate the average case under a random data distribution. For example, in the aforementioned example, since the input array is shuffled, the probability of element \(1\) appearing at any index is equal. Therefore, the average number of loops for the algorithm is half the length of the array \(n / 2\), giving an average time complexity of \(\Theta(n / 2) = \Theta(n)\).
However, calculating the average time complexity for more complex algorithms can be quite difficult, as it's challenging to analyze the overall mathematical expectation under the data distribution. In such cases, we usually use the worst-case time complexity as the standard for judging the efficiency of the algorithm.
Why is the \(\Theta\) symbol rarely seen?
Possibly because the \(O\) notation is more commonly spoken, it is often used to represent the average time complexity. However, strictly speaking, this practice is not accurate. In this book and other materials, if you encounter statements like "average time complexity \(O(n)\)", please understand it directly as \(\Theta(n)\).